(続)現環境最強のテーブルデータ向けモデルTabICLの紹介
 この記事をシェアする
この記事をシェアする



はじめに
こんにちは、DX Technology DivisionでMLOps/データ基盤回りの開発を行っている福嶋です。
ここ数年で、機械学習コミュニティの関心はLLMや画像生成AIに大きく傾いています。ChatGPTの登場以降は特に顕著で、「AIといえば生成系」という雰囲気がカンファレンスや技術記事でも漂っています。
しかし実際のビジネス現場に目を向けると、売上予測・顧客離反予測・不正検知・リスクスコアリングといった構造データ(テーブルデータ)を対象とした分類・回帰タスクは依然として中心的な役割を担っています。生成AIブームの陰に隠れているだけで、この領域のモデル研究も着実に進化しています。
本記事では構造データ向け分類モデルの最新動向に改めて目を向け、2023年10月公開の「現環境最強のテーブルデータ向けモデルTabPFNの紹介」で紹介したTabPFNを除けば最も注目すべき手法のひとつである TabICL[1] を中心に解説します。
TabPFN一強の時代から「TabPFN・TabICL二強体制」へ
以前の記事(現環境最強のテーブルデータ向けモデルTabPFNの紹介)では、TabPFN(Tabular Prior-Fitted Network)[2]を「現環境最強のテーブルデータ向けモデル」として紹介しました。小規模データにおいてXGBoostやLightGBMといった木系モデルを上回る精度をチューニングなしで実現するというインパクトは大きく、発表当時大きな注目を集めました。その後、TabPFN-2.5[3]へとさらなる進化を続けています。
しかし2025年以降、TabICL(およびその後継TabICLv2[4])が登場し、複数の権威あるベンチマークでTabPFNと並ぶ、あるいは一部で上回る性能を示しました。現在は TabPFNとTabICLの二強体制 と言えるのが実状です。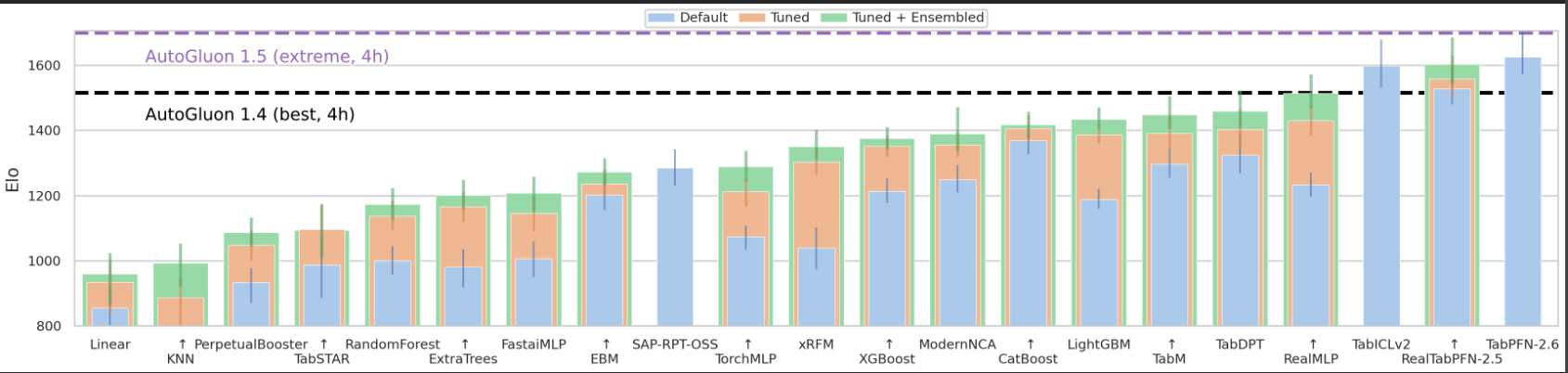
TabArenaにおけるオープンデータセットによるモデル間精度比較(TabArena[6])
このTop2のモデルに共通する仕組みがIn-Context Learning(ICL)です。
In-Context Learning(ICL)とは何か
In-Context Learningの初出は「Language Models are Few-Shot Learners」[5]と呼ばれるLLMのテキスト生成に関する論文であり、既に学習されたモデルにコンテキスト(文脈)を与えることで(事後確率上)最も妥当な解を予測することを指します。
例えば、
と与えられても何を答えるべきかわかりません(ポジネガなのか要約なのか)。一方
という入力があれば、「ポジネガ分析を求められている」ことをモデルが把握できるので、「もう二度と出ない」が「ネガティブ」に対応することがわかります。
これを機械学習で実現しようとしているのがTabPFNやTabICLです。
従来の機械学習モデルは、学習データを使ってモデルのパラメータを更新(勾配降下法など)することである特定のモデルを獲得します。一方ICLでは、事前に様々な因果モデルを学習しておき、学習データ自体をTransformerの「文脈(コンテキスト)」として入力することで妥当な因果を選ぶ形でモデルを獲得します。
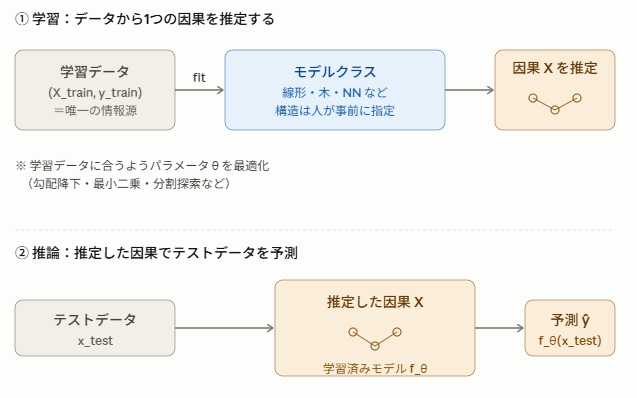
従来の学習イメージ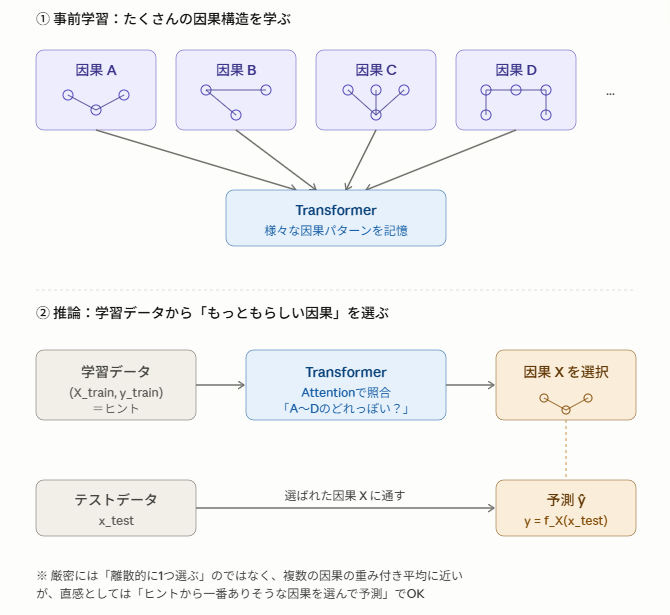
TabICLの学習イメージ
モデルは事前に大量の合成データセット上でこの「文脈から学ぶ」能力を学習しており、新しいタスクに対してはパラメータ更新なしに即座に対応できます。この仕組みにより、ハイパーパラメータチューニングが不要になります。
(機械学習も生成AIにのみ込まれかけているということですね。)
TabPFNとTabICLの比較
同じICLを用いていますが、両者には重要な設計上の差異があります。
アーキテクチャの違い
TabPFN v2.5 は、列(feature)方向と行(sample)方向のアテンションを交互に繰り返す設計を採用しています。これにより高い精度を実現していますが、学習データが増えるほど計算コストが急増するという制約があります。そのため、サンプル数やカラム数に制限があり、業務上課題があるケースも存在しました。
TabICL はこの問題を解決するために、2段階のアーキテクチャを採用しました。
- Stage 1(列→行アテンション): 各サンプルを「列方向アテンション」→「行方向アテンション」の順に処理し、サンプルごとに固定次元の埋め込みベクトルを生成する
- Stage 2(ICL Transformer): 生成された固定次元の埋め込みを使って、効率的にICL推論を実行する
固定次元の埋め込みを一度作ることで、Stage 2の計算コストはサンプル数に依存しなくなります。これにより、大規模データへのスケールが可能になりました。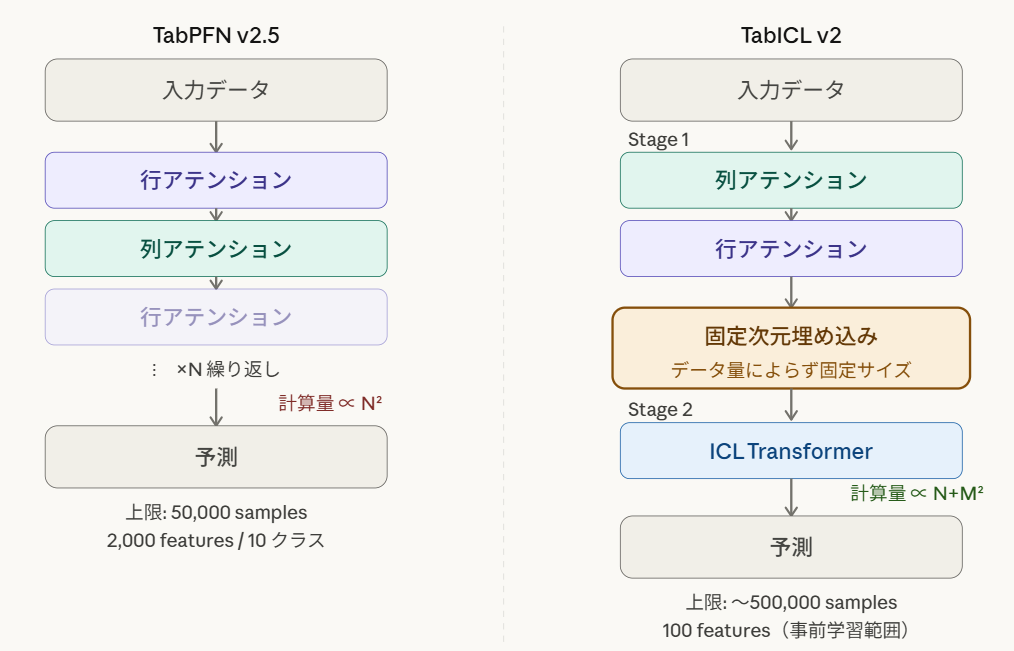
TabPFN vs TabICLのアーキテクチャ比較外観
スペックの比較
| 項目 | TabPFN v2.5 | TabICLv2 |
|---|---|---|
| リリース時期 | 2025年 | 2026年 |
| 対応サンプル数 | ≤ 50,000 | ≤ 500,000 |
| 対応特徴量数 | ≤ 2,000 | ≤ 100(事前学習範囲) |
| 対応クラス数 | ≤ 10 | 制限なし |
| 推論速度(H100 GPU) | 基準 | 約10倍高速 |
| アーキテクチャ | 行↔列アテンション × N回 | 2段階(固定埋め込み→ICL) |
| スケーリング特性 | O(N²) | O(N + M²) |
ベンチマーク上の位置づけ
2025年に公開された生きているベンチマーク TabArena[6]では、小規模データ(≤10K samples)ではTabPFN v2が他を大きく引き離してトップ、中規模データ(≤100K)ではTabICLがTabPFN v2・CatBoostを上回るという棲み分けが確認されています。
また TALENT[7]ベンチマーク(200分類データセット)でも、TabICLはTabPFN v2と同等の精度を維持しながら最大10倍の速度優位を示しています[1]。
チューニングなしの状態でXGBoost・CatBoost・LightGBMのチューニング済みモデルをTabArena上の約80%のデータセットで上回るというのは、実用上かなり強い結果です。
現状ではかなり大規模なデータに対しては従来の木系モデルが優勢ではありますが、現状の進化速度を見る限りいつ追いつかれてもおかしくはありません。
| 状況 | 推奨 |
|---|---|
| データが小規模(< 5K)でクラス数≤10 | TabPFN v2 |
| データが中規模(5K〜100K)または多クラス | TabICL / TabICLv2 |
| 大規模(100K〜)、解釈性重視 | LightGBM / CatBoost(アンサンブル) |
TabICLの利用方法
TabICLはTabPFNと同じくscikit-learn準拠のAPIで使えます[8]。
bash
学習と推論は内部的に単一のforwardパスで実行されるため、fit と predict は事実上セットです。
パラメータ更新も存在しないため、高速な推論が可能です。
まとめ
生成AIの陰に隠れつつも、テーブルデータ向け分類モデルの研究は着実に進化しています。TabPFNが切り拓いたICLというパラダイムはTabICLによってさらに発展し、チューニングなし・単一forwardパス・中規模データまで対応という高い実用性を持つモデルが登場しました。
XGBoostやLightGBMに慣れ親しんだ方にとって、TabICLは一度試す価値のある選択肢です。特に「素早くベースラインを引きたい」「小〜中規模データで木系モデルの精度が頭打ちになっている」といった場面で、その恩恵を実感しやすいでしょう。
参考文献
- [1] Qu et al., "TabICL: A Tabular Foundation Model for In-Context Learning on Large Data", ICML 2025
- [2] Hollmann et al., TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second, arXiv 2022
- [3] Grinsztajn et al., "TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models", arXiv 2026
- [4] Qu et al., "TabICLv2: A better, faster, scalable, and open tabular foundation model", arXiv 2026
- [5] Brown et al., "Language Models are Few-Shot Learners", arXiv 2020
- [6] Erickson et al., "TabArena: A Living Benchmark for Machine Learning on Tabular Data", NeurIPS 2025, https://huggingface.co/spaces/TabArena/leaderboard
- [7] LAMDA-Tabular/TALENT · Datasets at Hugging Face
- [8] soda-inria/tabicl: TabICLv2: A state-of-the-art tabular foundation model


