LLM評価の現実と対策:LLM as a Judge実践で学んだ課題解決法
 この記事をシェアする
この記事をシェアする



はじめに
こんにちは、AIエンジニアの芹澤です。最近は生成AIを活用したアプリ開発の案件に取り組んでいます。
生成AIは直近でもOpenAIからGPT-5が登場したり、AnthropicがClaude Opus 4.1とClaude Sonnet 4を発表、GoogleもGemini 2.5 Proを展開するなど、各社が次々と新モデルを投入し、進化が目まぐるしいですね。そんな中、生成AIを組み込んだアプリ開発も盛んにおこなわれており、多くの企業や個人がアプリをリリース・展開しています。この記事を読んでくださっている方の中にも、生成AIアプリを開発しているという方が多いのではないでしょうか。
ただ、皆さんは開発した生成AIアプリに利用されているLLMの性能評価をどのように行っているでしょうか。アプリ内におけるLLMの性能は、アプリそのものの評価にも繋がってくる重要な要素ですが、まだ確立された評価方法はないかと思います。弊社でも、生成AIアプリのLLMの性能評価方法は課題の一つです。
今回は、私が開発に携わっている生成AIアプリで行っているLLMの性能評価の方法として、LLM as a Judgeを活用した評価方法を紹介します。
LLM as a Judgeとは何か
基本概念と従来手法との比較
LLM as a JudgeはLLM自身を評価者として活用する手法です。例えば、GPT-4oとGPT-5を用いた文章生成の2つを比較したい場合、評価用のLLMを1つ用意し、「GPT-4oで作成した文章とGPT-5で作成した文章の2つを比較し、どちらが優れているかを判断してください。」などと指示することで評価する方法です。ただし、このような簡単なプロンプトでは後述の通り課題があるので、より細かく指示を出します。
LLM as a Judgeは従来の評価指標の限界を克服する新しいアプローチとして注目されています。従来の評価で多く用いられてきた手法として、BLEU・ROUGEなどの自動評価指標があります。これは、表面的な文字列マッチングに依存するため、人間の評価と比べても相関性が低く、生成AIの出力品質評価には向かないという問題がありました*1。また、人間による評価では、微妙なニュアンスも捉えることができ最も高品質ですが、コストと時間がかかるため、データ量が多い場合は現実的ではないという問題がありました。そこで、LLMを用いた評価が注目されるようになりました。LLMは文脈や意図を理解した評価が可能で、自動評価でありながら高い評価品質を実現しています。また、正確性や流暢性など、複数の観点からの評価を同時に行うことが可能です。
|
評価手法 |
精度 |
コスト |
スケーラビリティ |
|---|---|---|---|
|
BLEU/ROUGE |
表面的な文字列マッチングのため、意図などは捉えられず、低い。 |
ほぼ無料 (計算コストのみ)。 |
瞬時に大量処理が可能。 |
|
人間による評価 |
微妙なニュアンス等も捉えられ、最も高い。 |
人的リソースコストがかかる。 |
人間の目視評価のため、限りがある。 |
|
LLM as a Judge |
意図などもある程度捉えられ、高い。 |
APIの利用コストがかかる。 |
大量処理が可能。 |
4つの主要評価方法
LLM as a Judgeは、求めたい結果に応じて4つのタイプのプロンプト設計による評価方法があります*2。
-
スコアリング
1~10段階評価のような離散スコア、0~100の範囲を用いた連続スコアのようにスコアリングすることで評価を行います。段階評価により細かい品質差を評価したり、正確性・流暢性など複数観点を同時評価して総合点で決定するなどが可能です。 -
Yes/No判定
Yes/Noの2択で判断されるので、曖昧性を排除した評価が可能です。 -
ペアワイズ比較
2つの選択肢を直接比較し、Win/Tie/Lossで相対評価を行います。人間の評価と高い一致性が見られるとされています。 -
多肢選択
複数の選択肢から適切なものを選択します。複数の候補があるなど複雑な評価場面で活用することができます。
開発での活用事例
システム概要
私の携わっている案件では、社内文書検索システムを組み込んだWebアプリを開発しています。ざっくりとしたシステムのフローは以下のようになっていて、社内文書は事前にLLMによって要約・データベースに登録され、そこから検索されてユーザに提示される仕組みになっています。そこで、複数のLLMモデルを比較し、要約される文章の精度評価が必要となりました。
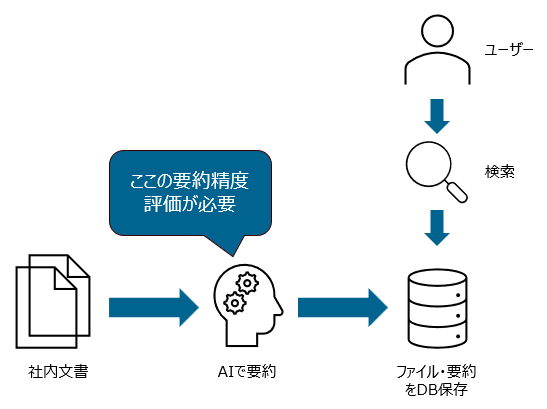
社内文書検索システムの主なフロー
評価観点
今回の開発では、以下に示す3つの評価がポイントとなりました。
-
要約品質:文書の意図に沿った要約が生成されているか
-
要約速度:前処理を含む文書の要約処理にどの程度時間がかかるか
-
コスト:1文書当たりの処理にかかるAPIのコストはどの程度か
この中で、要約品質についてはLLM as a Judgeで判断することが出来ると考え、活用、検証を行いました。
LLM as a Judgeのプロンプト
今回使用したLLM as a Judge用のプロンプトの1つを紹介します。評価方法としては、スコアリングとペアワイズ比較を合わせた方法による評価を実施しました。元の社内文書と要約文章を与えて比較させ、5つの観点でそれぞれスコア付けして評価を行い、最後に総合的に優れているものを選択させるというものです。スコアを100点区切りにした理由としては、細かすぎる刻み(1点刻みなど)では評価の一貫性を保つのが困難という実践的な経験に基づいています。また、後で結果の確認を行えるよう、判断した理由も出力させるようにしました。
LLM as a Judgeによる評価結果
上記プロンプトを用いてLLM as a Judgeによる評価を行ったところ、上手く評価できたケースと上手く評価が出来なかったケースがありました。そこで、今回は評価を行った文書の中でも後述するPosition Biasが発生していると思われる文書に対し、目視による評価を行うことで性能評価の正しさを担保しました。
なぜ正しく評価できないケースが発生したか~LLM as a Judgeの課題と解決策~
今回の開発における性能評価で上手くいかなかった理由として、複数の理由が考えられます。LLM as a Judgeで評価を行う際に注意が必要な課題と解決策については、以下のようなものがあります。
課題1:評価基準の曖昧性
LLMに評価を行わせる際は、「関連性が高い」「有用である」といった抽象的な基準で指示をした場合、評価が困難になります。そこで、前述したとおり、具体的な評価観点とスコアリング基準を明文化したプロンプト設計を行うことが重要となります。
課題2:評価の一貫性とバイアス
LLM as a Judgeでは、同じ入力を与えても異なる評価結果が出力されることがあります。これは、LLMに内在する複数のバイアスが原因となります。
-
Position Bias:評価対象の順序により、結果が変わることがあります。そこで、評価対象の順番を入れ替えて複数回評価を行い、結果の一貫性を確認することが必要となります。
-
Length Bias:より長い、場合によっては冗長な回答を好む傾向があります。そこで、プロンプトで長さに関する明示的な評価基準を与える必要があります。
-
Concreteness Bias:数値や権威的な情報源を含む回答を過度に評価することがあります。そこで、具体性と正確性の分離評価を行うことが求められます。
-
Self-Enhancement Bias:自分が生成した回答 (同一モデル) を好む傾向があります。そこで、評価用と生成用で異なるモデルを使用する必要があります。
-
Style Bias:特定の文体やトーンを好むことがあります。プロンプトでこれらが評価観点にならないよう示す必要があります。
今回の原因と解決策
今回の開発では特にPosition Biasの影響が大きかったと考えています。上手く評価できていなさそうなケースを確認すると、評価順序を入れ替えても先に評価されるほうが優秀と判定されてしまっており、結果の一貫性が担保できなかったと思われます。また、評価基準の曖昧性が残っており、各評価点の基準を示せていなかったのも原因の一つとして考えています。解決策としては、プロンプトの各評価点基準の追加とChain-of-Thought (CoT) を用いたプロンプト改修を考えています。現在は5つの評価観点を1回の思考でまとめて評価を行っていますが、CoTによる段階を踏んだ評価を行わせることで、より正しい評価に繋がるのではと考えています。
まとめ
本記事では実際の開発におけるLLM as a Judgeの活用事例についてご紹介しました。LLM as a Judgeは大量の評価対象文書に対して効率的に評価を行える手法です。今回はLLMによる評価には課題が一定残り、人手での評価と併用するという形になりましたが、評価用プロンプトをより充実させることで、LLM as a Judgeだけでも精度の高い評価ができると考えています。今回の知見が皆様の参考になれば幸いです。
参考文献
*1: A list of metrics for evaluating LLM-generated content
*2: A Survey on LLM-as-a-Judge


