"それっぽい画像"はなぜ生まれるのか──生成AIを実用化するための分業アーキテクチャ
 この記事をシェアする
この記事をシェアする



第ゼロ章 はじめに
こんにちは、ARISE analytics の大塚です。私が所属するチームでは、AIに時事情報を調査させて、自社への影響について示唆を出してもらうアプリの開発を行っています。
近年、大規模言語モデル(LLM)と画像生成AIの進化は目覚ましく、テキスト情報からリッチなビジュアルコンテンツを生成する「Text-to-Image」は多くの場面で活用されるようになってきました。しかし、複雑な情報を、意図通りに「読める」形で画像化することには、依然として高い壁があります。
みなさんの中にも、指示したレイアウトで画像を生成できない、文字量が多くて読みにくい、ハルシネーションが起きるなど、画像生成のチューニングの難しさを経験したことがあるのではないでしょうか。
本記事では、私たちが開発するアプリで直面した「それっぽいけど、読めない画像」という課題を、アーキテクチャの転換によってどう乗り越えたのか、その技術的挑戦の裏側を解説します。
この記事のキーワード
- Nano Banana
- Attention Dilution
- Lost in the Middle
- Instructional Distraction
- LLMの専門化
第一章 テキストだけでは伝わりきらない情報──なぜビジュアル化が必要だったのか
私たちのプロジェクトの目的は、膨大な時事情報の中から顧客のビジネスに影響を与えうる情報を抽出し、「動向変化の先読み」と「早期のリスク検知」を強化することです。当初は、分析結果をテキスト中心のレポートとして提供していました。
▼画像生成導入前の情報提供フロー
- 最新の時事情報を収集
- 生成AIが重要情報を選定
- 生成AIによる調査を踏まえて「自社への影響」を要約・分析
- 自社への影響や注視すべき論点を、テキストレポートとして提供
広範な時事情報から重要トピックを抽出し、能動的に配信するこのアプローチは「情報収集の時間が短縮された」といったユーザーからの評価をいただく一方で、致命的な課題も浮き彫りになりました。
🚩 テキストベースの課題
- 訴求性の欠如:重要なリスク情報であっても、テキストのみでは多忙なユーザーの印象に残らず、見落とされるリスクがある
- 視認性の悪化:情報過多なテキストは、直感的な理解を妨げ、重要な情報の把握に時間を要してしまう

結局、情報を抽出し、追加で示唆を載せたレポートを生成しても、ユーザーが情報を「精読」しなければ価値が伝わらない状況でした。つまり、ユーザーが「読む」という行為から解放されず、真のUX向上には至っていませんでした。
この状況を打破し、情報の「認知」から「判断」までを最短化するため、私たちは情報を構造化して伝えることができる、画像生成AI「Nano Banana」の導入を決定しました。
第二章 新たな挑戦と「それっぽい画像」の罠
第一節 画像生成AI Nano Bananaとは
Googleが開発した画像生成・編集を行うAIモデル、通称「Nano Banana」はテキストから高品質な画像を生成することに特化した高性能なツールです。単に指示された内容を描画するだけでなく、生成される画像の視覚的な品質と美的訴求を最大化するよう設計されている点に、その最大の特徴があります。
つまり、「人間にとって魅力的で、理解しやすいビジュアルアセットを生成する」という役割を担います。私たちはこれを、単なる画像生成エンジンとしてではなく、LLMが構造化したデータを洗練されたインフォグラフィックへと昇華させる「ビジュアルレンダリングエンジン」として位置づけました。
第二節 Text-to-Imageへの挑戦
「情報を読む」負担からユーザーを解放するという目標を掲げ、私たちはテキストから画像を生成する「Text-to-Image」の本格的な実装に着手しました。
しかし、複雑な時事情報や「自社への影響」といった高度なビジネス考察を、単なる"雰囲気の絵"ではなく、一目で理解できる「構造化されたインフォグラフィック」としてAIに出力させることは容易ではありません。時事情報をAIに理解させ、レイアウトや配色といったデザイン要素にまで落とし込んで、的確な指示を出すための新たな仕組みが必要でした。
この課題を解決するため、私たちが構築した実装アーキテクチャは以下の通りです。
▼最初に試した画像生成フロー
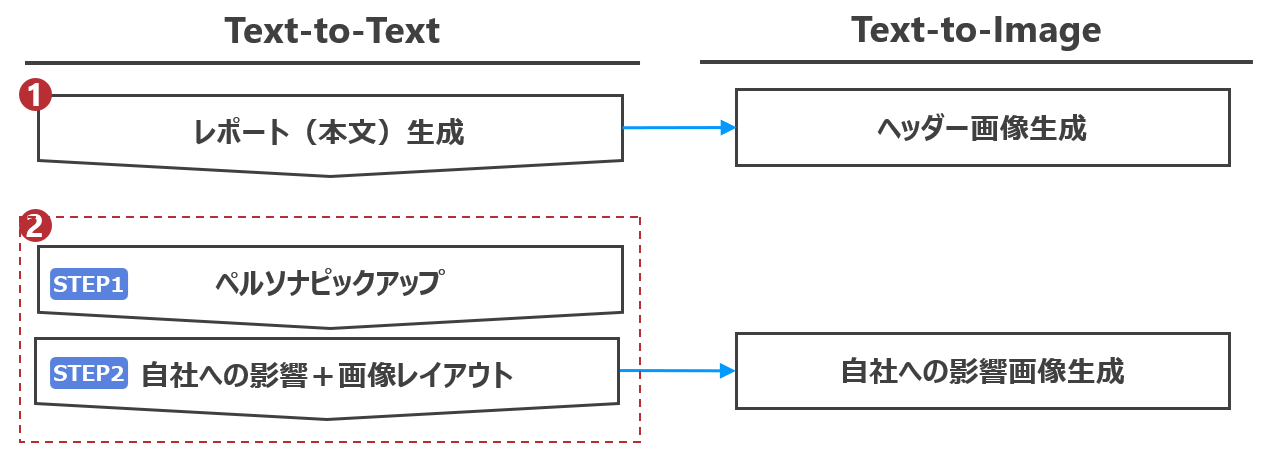
まずレポート記事のヘッダーとなる「レポート本文」を生成し、その後「自社への影響」の考察と画像レイアウト生成を行う、2段階のプロセスで構成していました。
1. レポート本文とヘッダー画像の生成
- テキスト生成:生成AIが調査した内容から本文を生成
- 画像生成:表紙となる「ヘッダー画像」を生成
2. 「自社への影響」の分析と画像レイアウト生成
画像生成AIに渡すための、考察テキストと画像レイアウト案を生成します。このプロセスは、以下のプロセスで構成されていました。
■STEP1
ペルソナピックアップ:自社データを分析し、影響のある自社顧客層をペルソナとして推測■STEP2
考察・画像レイアウト生成:ペルソナと生成AIによる調査結果を基に、「自社への影響」に関する考察テキストと、その内容を視覚化するための画像レイアウト案(配色、フォントなど)を同時に生成
このように、当初のアーキテクチャでは、「自社への影響」の考察テキスト生成と画像レイアウトの指示を、単一のLLMにまとめて依頼する流れになっていました。
しかし、この方法が生み出したのは、一見すると内容がきれいにビジュアライズ化されているものの、肝心な情報が伝わらない「それっぽいけど、読めない画像」でした。
▼「それっぽいけど、読めない画像」の例
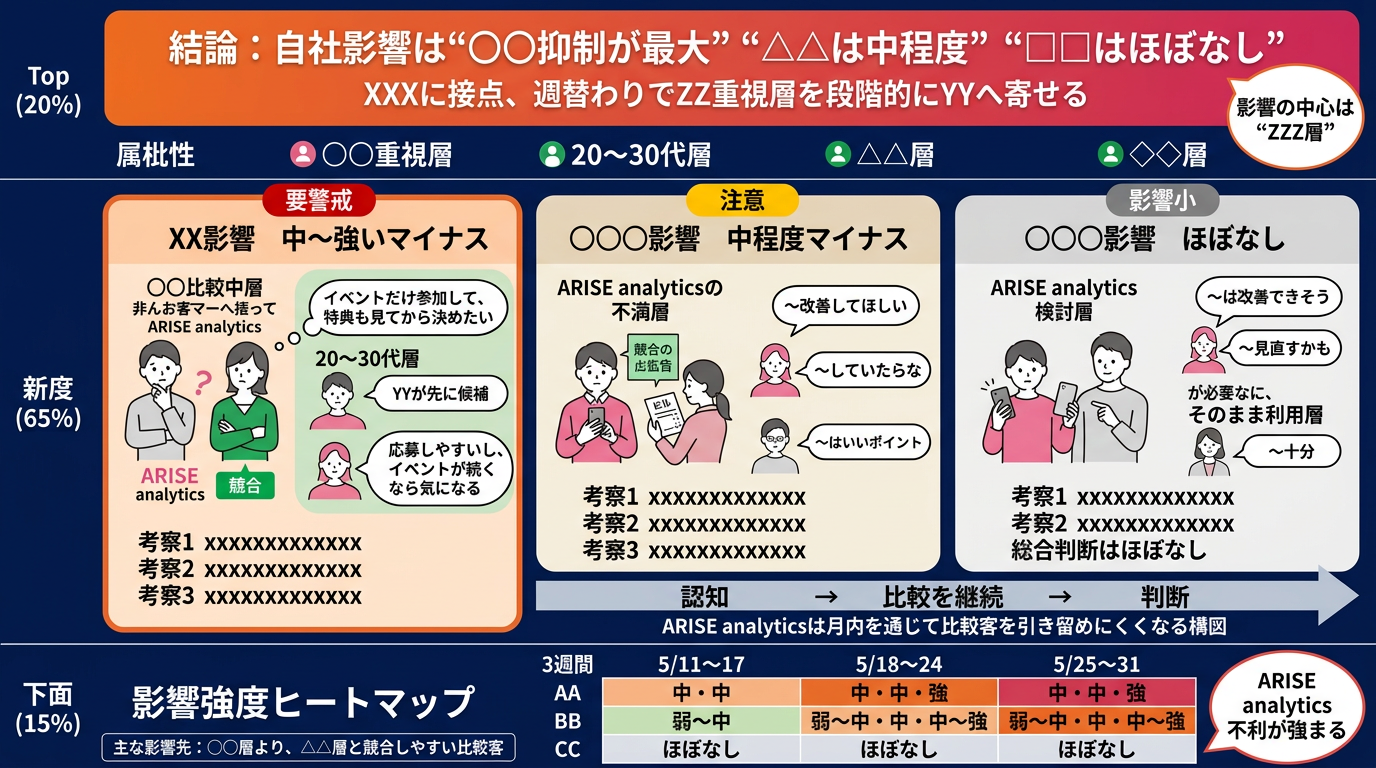
第三節 「それっぽいけど、読めない」の正体 ─ AIが抱える弱点とは
「それっぽいけど、読めない画像」になった要因は、「情報の焦点のぼやけ」と「"指示"と"内容"の混同」にあると考えられます。
🚩【情報の焦点のぼやけ】
- 依然として多くのテキストが出力され、「何が結論で、何が根拠か」が分からない。
- 大量のテキストが理路整然に配置されておらず不明瞭になっている。
この原因は、画像生成AIが正確に処理できる「情報の容量」の限界にありました。
最初に試したアーキテクチャでは、自社への影響考察と画像レイアウト案として、大量のテキストをそのまま画像生成AI「Nano Banana」に渡していました。Nano Bananaは高性能なため、大量のテキストを渡しても、一見すると構成や配置が整った綺麗なレイアウトを生成してくれます。
しかし実際には、画像内に大量の文字情報がメリハリなく流し込まれてしまい、結果として「何が結論で、何が根拠か」が直感的に理解できない画像になってしまいました。
この背景には、AIの言語処理における"Attention Dilution(アテンションの希薄化)"という技術的な問題があります。[1][2]
これは、入力される文字(トークン)が多すぎると、AIが各単語の関連性を計算する「自己注意機構(Self-Attention)」の重みが分散し、本当に重要な情報へのフォーカスが薄れてしまう現象です。近年では、LLM研究でも"Lost in the Middle(中盤の情報の喪失)"とあわせて課題視されています。[3]
この現象はテキスト生成AIでも起こり得ますが、画像生成AIでは「すべての情報を1枚の固定されたキャンバスに同時に圧縮しなければならない」という構造的な制約があるため、より致命的な結果を招きやすいと考えられます。
テキスト生成AIであれば、長文を順番に出力することで文脈を保つことができます。しかし画像生成AIの場合、アテンションが希薄化した状態で大量の文字を1枚の絵に落とし込もうとすると、「どこを強調すべきか」という焦点を見失います。その結果、重要度に関係なく文字を均等に配置しようとしてしまい、「直感的に理解できない、情報の焦点がぼやけた画像」になっていたのです。
つまり、レイアウト自体は組めても、「どの情報を一番大きく強調すべきか」という情報の優先順位をAIの中で判断できなくなっていた、ということです。
🚩【"指示"と"内容"の混同】
- レイアウト指示(メタ情報)自体を、LLMが「描画すべきテキスト」と誤認し、画像内に出力してしまう問題
この原因は、「画像に描画すべきテキストの生成」と「画像レイアウトの指示」という、全く異なるタスクを1つのLLMに同時に行わせていたことにあります。
近年のLLM研究では、処理対象のテキスト内に「指示のように見える情報」が含まれると、LLMが本来のユーザー指示と入力内容を混同し、意図した処理から逸脱することが指摘されています。Hwang et al. はこの現象を "Instructional Distraction(指示による攪乱)" と呼び、明示的に区別を促しても、LLMが入力内の指示らしき文に引っ張られる場合があることを示しています。[4]
最初に試したアーキテクチャで起きていた問題も、構造としてはこれに近いものでした。「出力すべき文章を生成する指示」と「裏側のレイアウト指示」が一度に同じプロンプト内に同居していたため、AIが情報を混同し、レイアウト指示の文字列まで「描画すべき重要なテキスト」と誤認して出力してしまっていたのです。そして、それを受け取った画像生成AIも指示通りに文字を印字し、「読めない画像」を生み出す原因となっていました。
結果として、これら「画像生成AIの容量オーバー」と「単一LLMの役割オーバー」の2つが重なり、"ぱっと見は綺麗だけれど、情報が破綻していて読めない画像"が生成されてしまっていました。
💡 補足知識
-
Attention Dilution
入力情報が多くなると、「最も関連性の高い部分に集中する能力」が低下し、本来注目すべき部分への重みが軽減されてしまうこと。
-
Lost in the Middle
重要な情報が文章の最初や最後にある場合は抽出できても、大量のテキストの真ん中に埋もれていると、AIがその情報をうまく利用できず、パフォーマンスが著しく低下すること。
-
Instructional Distraction
LLMがタスクを処理する際、プロンプト内に含まれるタスクに無関係な情報や別の指示のような情報に注意を奪われ、本来のタスクの推論精度が低下したり、誤った出力をしてしまう現象のこと。
第三章 「読めない画像」からの脱却 ─ 「統合」と「分離」のアーキテクチャ刷新
Nano Bananaの性能を最大限に引き出すため、私たちはアーキテクチャを根本から見直しました。そこで導き出した結論は、上流の情報処理プロセスを統合・整理しつつ、下流のLLMの役割を明確に分割することでした。
具体的には、以下の2つのポイントでアーキテクチャを刷新しました。
✅【アーキ改善1】サマライズ層の新設:入力情報の最適化
まず、情報過多による精度低下を防ぐため、長文読解が得意なLLMに「情報の取捨選択と要約」だけを専門に行わせる層を「レポート(本文)生成」に新設しました。これにより、後続のAIには「本当に必要な情報だけ」が渡されるようになり、情報のボトルネックと焦点のぼやけを解消しました。
✅【アーキ改善2】「テキスト」と「画像レイアウト」の完全分離:役割の専門化
最も重要な改善が、このタスク分離です。私たちは、「何を描くか(What)」を担当するLLMと、「どう見せるか(How)」を担当するLLMを完全に分離しました。
- コンテンツLLM:調査結果の分析のみに集中し、描画すべき内容を構造化されたテキストデータとしてのみ出力する
- レイアウトLLM:コンテンツLLMが作った構造化データを受け取り、それをどう配置するかという最終的なレイアウト指示の生成に特化する
この分離により、コンテンツLLMは「自社への影響をどう整理して伝えるか」に集中でき、レイアウトLLMは「情報をどう見せれば読みやすいか」という設計に集中できるようになりました。
その結果、レポートごとに情報量が変動してもレイアウトが破綻しにくい、安定した画像生成パイプラインが完成したのです。
▼新画像生成フロー
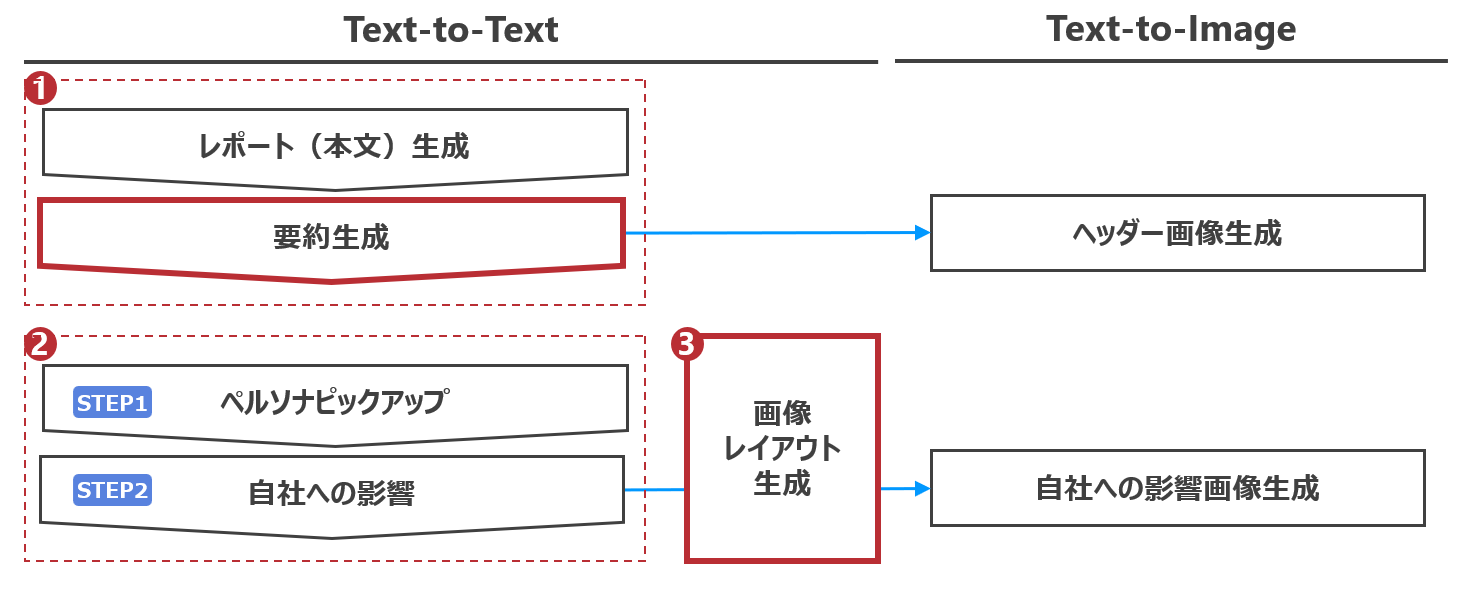
新アーキテクチャでは、Nano Bananaに渡すプロンプトを生成するプロセスを、考察とレイアウト指示が混在した状態から、以下の3段階に刷新しました。
1. 要約とヘッダー画像生成
生成AIが調査した結果の中で重要情報を絞り込む
2. コンテンツ生成
自社への影響を構造化して整理する
3. 画像レイアウト生成
構造化済みの情報を、読みやすい見せ方に変換する
新旧のプロセスの違いを整理すると以下のようになります。
| 処理フロー | 旧アーキテクチャ | 新アーキテクチャ |
|---|---|---|
| 1 | 収集した情報からレポート本文を生成 | 収集した情報からレポート本文とサマリを生成 |
| 2 | 「自社への影響」調査・分析と画像レイアウト生成 | 「自社への影響」調査・分析の結果を生成 |
| 3 | ― | 画像レイアウト生成 |
このように、新アーキテクチャでは、まず要約処理によって調査結果の重要情報だけを抽出し、そのうえで「自社への影響」という伝えるべき内容を構造化したうえで、最後にレイアウト専用のLLMが見せ方だけを設計する構成へと改めました。
その結果、1枚の画像に流し込まれる情報量が適切に絞られ、本当に必要な情報が整理された状態で画像生成AIに渡されるようになりました。さらに、コンテンツ生成とレイアウト生成の役割を分離したことで、強調すべき要点、見出しの階層、情報の配置に一貫性が生まれています。
新アーキテクチャによって、「それっぽいけど、読めない画像」から、ユーザーがひと目で要点をつかみ、自社への影響を短時間で把握できる"読める画像"へと変化したのです。
▼「読める画像」の例

第四章 まとめと今後の展望
単一のLLMに複雑なタスクを丸投げするアプローチは、限界に達しやすいのが現実です。私たちの経験が示すように、タスクを適切に分解し、それぞれの処理に特化したLLMを連携させるアーキテクチャは、より堅牢で質の高いアウトプットを生み出します。
今回は、
- 調査情報を要約して絞り込む
- 自社への影響を構造化して整理する
- レイアウト指示を別LLMに分離する
という設計に切り替えることで、高密度な分析情報を、視認性の高い"伝わる"ビジュアルへと昇華させることに成功しました。
今後は、ユーザーからのフィードバックを基にレイアウトパターンを改善し、情報の種類や重要度に応じて最適な見せ方を自動で選択できるような、より発展的な仕組みも視野に入れて開発を進め、「動向変化の先読み」と「早期のリスク検知」のさらなる強化をしていきたいと考えています。
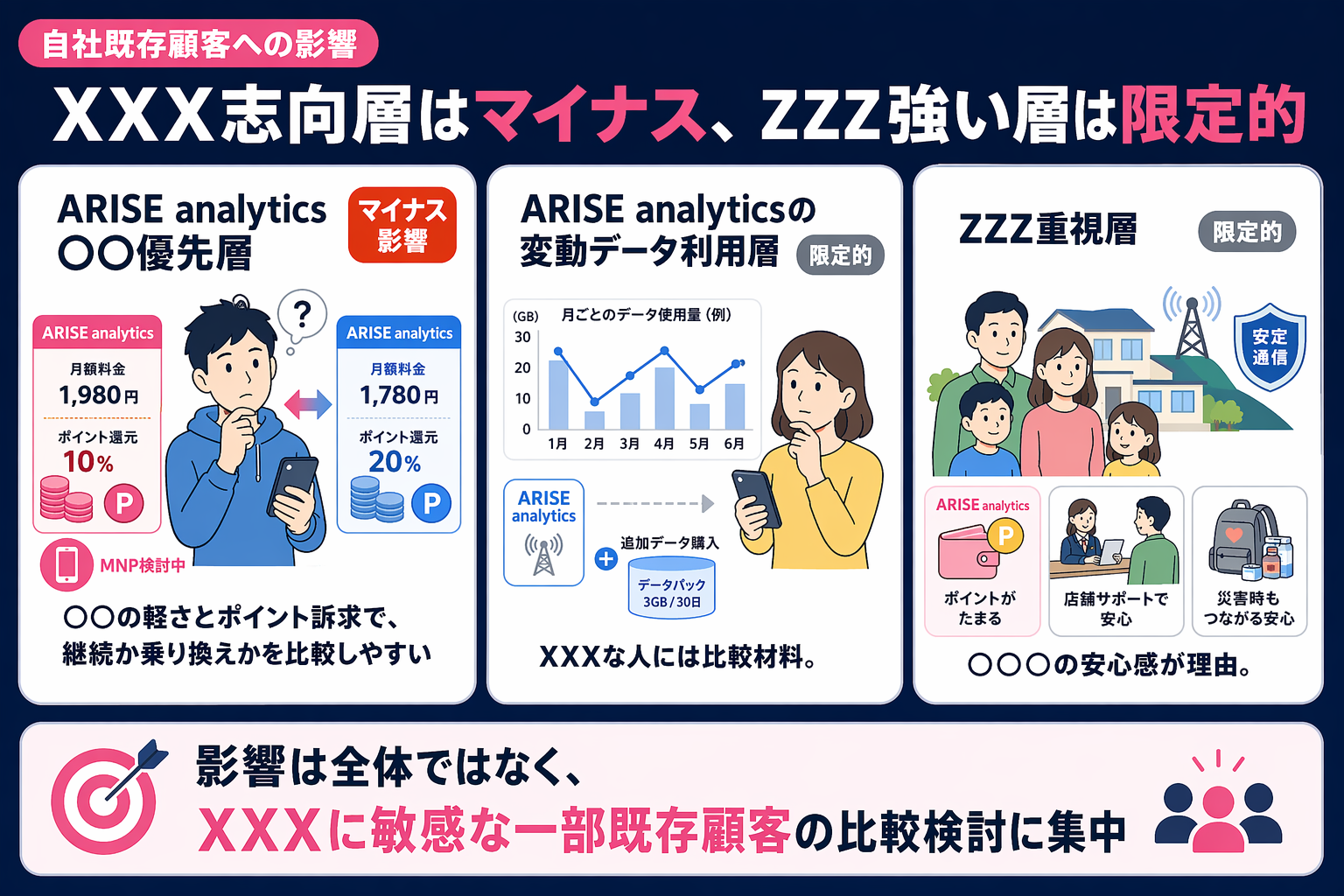
コラム〜画像生成AIの使い分け
近年は、Nano Banana に加え、OpenAI の GPT Image2 のような高性能な画像生成モデルも登場し、画像生成AIの選択肢は広がっています。こうした流れの中では、つい「どのモデルが最も高性能か」という観点に注目しがちです。
しかし実際には、同じ情報を基に画像を生成しても、モデルによって、文字情報の扱い方、レイアウトの安定性、ビジュアルの訴求力にはそれぞれ傾向があります。つまり、現在の画像生成活用は、単に"最強のモデル"を選ぶ段階ではなく、モデルの特性を踏まえて、どのように情報を設計するかが重要になる段階に入っているといえます。
今回私たちが向き合った課題も、まさにこの点にありました。重要だったのは、モデルの性能に頼り切ることではなく、画像生成AIが処理しやすい形に情報を整理して渡すことだったのです。
▼GPT Image2が生成した画像
参考文献
[1] Yixiong Fang, Tianran Sun, Yuling Shi, Xiaodong Gu. AttentionRAG: attention-guided context pruning in retrieval-augmented generation. arXiv, 2025
https://doi.org/10.48550/arXiv.2503.10720
[2] Huyu Wu, Meng Tang, Xinhan Zheng, Haiyun Jiang. When language overrules: revealing text dominance in multimodal large language models. arXiv, 2025
https://doi.org/10.48550/arXiv.2508.10552
[3] Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, Percy Liang. Lost in the middle: how language models use long contexts. arXiv, 2023
https://doi.org/10.48550/arXiv.2307.03172
[4] Yerin Hwang, Yongil Kim, Jahyun Koo, Taegwan Kang, Hyunkyung Bae, Kyomin Jung. LLMs can be easily confused by instructional distractions. arXiv, 2025
https://doi.org/10.48550/arXiv.2502.04362