GPT-OSS Safeguardが拓く新たな潮流 — ガードレールモデルの分類と実務への適用①
 この記事をシェアする
この記事をシェアする



ARISE analyticsの挺屋です。私は社内の生成AI活用推進を担当し、AIエンジニアとして、日々の開発現場で AI コーディングツールをどのように安全かつ効果的に使うかを検証・標準化しています。また、業務の過程でローカルLLMの話題に触れることも昨今は多くなってきました。そこで得られたローカルLLM知見のうち、本記事ではガードレールモデルの分類について紹介しようと思います。また、後続記事ではモデルを実際に触り、検証結果と実務適用への勘所を共有する2本立ての記事となっています。
この記事は、次のような方にぜひ読んでいただきたいと思っています。
-
ローカルLLM、ガードレールモデルについて興味がある人
- 特にGPT-OSS Safeguardについての動作感を知りたい人
ARISE analyticsでは生成AIの技術支援も行っています。生成AIを使った機能のプロダクト開発など実施されていますが、その際に避けては通れないのが安全性の議論です。プロトタイプ段階では「すごい!動いた!」で済みますが、いざ商用環境へリリースしようとすると、「発言・表現に攻撃性はない?」「競合他社の製品を推奨したら?」「プロンプトインジェクションで社外秘情報が漏れたら?」といった懸念が次々と湧いてきます。
あるいは、企業での生成AI活用のユースケースとして、社内の情報を精査したいというケースがあるかと思います。例えば、スライド資料や顧客情報などAIに投入する情報として適切か?、メールやチャットの内容で規約違反に当たるような疑義はないか?などがあげられます。それも1つの安全性の担保となります。
そのような安全性を担保するための仕組みとして、生成AIに有害な入力の精査を任せようというガードレールモデルの活用が進んでいます。有害なコンテンツを除外するコンテンツフィルタのような役割を生成AIが担います。事前に学習したコンテンツをはじくよう特化した、従来からある分類型(Classification-based)のガードレールに対して、はじきたい内容をポリシーとして動的に変更して判別できる推論型(Inference/Reasoning-based)のガードレールも登場しました。そこで各ガードレールモデルの特性を整理し、それぞれの長所・短所、そして実際のシステムでの使い分け基準について、技術的な視点から深掘りしてみたいと思います。
ガードレールモデルとは
そもそもガードレールモデルとは、LLMへの入力(プロンプト)や、LLMからの出力(レスポンス)を監視し、あらかじめ定義されたポリシーに違反していないかを判定する仕組みのことです。企業が生成AI(LLMなど)を実務に導入する際、AIが誤情報を流したり、差別的な発言をしたり、社外秘情報を漏らしたりするリスクを最小限に抑えるために不可欠な仕組みです。
ガードレールモデルは、ユーザーとAI(LLM)の間に介入し、入力プロンプトと出力の両方をチェックします。

入力ガードレール(Input Guardrails): ユーザーが入力したプロンプトを検査
-
ユーザーが入力したプロンプトをガードレールモデルが受け取ります。
- モデルは、そのプロンプトが「有害なコンテンツ(ヘイトスピーチ、違法行為の要求など)」「プロンプトインジェクションのような攻撃」「企業ポリシー違反(競合言及、機密情報入力など)」に該当しないかを判定します。
- 違反が検知された場合、LLMへの入力をブロックしたり、警告メッセージをユーザーに返したりします。問題がなければ、プロンプトをLLMへ渡します。
- 例:「爆弾の作り方を教えて」といった危険な質問や、システムを騙そうとする攻撃(プロンプトインジェクション)をブロックする。
出力ガードレール(Output Guardrails): AIが生成した回答を検査
-
LMが生成したレスポンスをガードレールモデルが受け取ります。
- モデルは、そのレスポンスが「ハルシネーション(誤情報)」「差別的な表現」「企業ポリシー違反」などを含んでいないかを判定します。
- 違反が検知された場合、レスポンスをブロックしたり、修正を促したりします。
- 問題がなければ、ユーザーにレスポンスを提示します。
- 例:AIがハルシネーション(嘘)をついていないか、差別的な表現が含まれていないかを確認する。
そのようにはじきたいコンテンツが含まれるのかどうかを判別するロジックは、そのロジックの性質に分類型(Classification-based)と推論型(Reasoning-based)の2つに大別されます。広くこのように呼ばれているわけではなく、本記事では説明上このように呼びます。分類型と推論型の定義をまとめるとこのようになります。
| 分類型 | 推論型 |
| 事前に学習された「有害データのパターン」に基づき、入力テキストが特定のクラス(暴力、ヘイトなど)に当てはまるかを確率的・機械的に判定する方式 例)ShieldGemma |
与えられた「ポリシー(判断基準)」をLLMがその場で読み込み、入力された内容の文脈や意図を論理的に思考して判定する方式
|
下記でそれぞれの特性を見ていきましょう。
ガードレールモデル分類と性質
従来のアプローチ:分類型ガードレール
分類型は、事前に学習されたデータパターンに基づき、入力されたテキストを分類する古典的アプローチです。基本的には SLM(小規模言語モデル)や、軽量な LLM を分類タスクに特化させて利用し、生成AIのガードレールモデルとして代表的なのは、ShieldGemma (Google)などがあります。
分類型では特定のデータセット(有害テキストと無害テキストのペア)でファインチューニングを行い、「このテキストは『暴力』『性的』『ヘイト』のいずれかに該当するか?」といったクラス分類を、確率スコア(0.0〜1.0)として出力させます。現在では文脈理解力の高い小規模な生成モデルを使うケースが多くなっています。
補足ですが、ShieldGemma ではこのように有害コンテンツの確率スコアを出しています。直接最終的なスコアが出てくるのではなく、プロンプトの続きとして「Yes(有害)」が来るのか、「No(有害でない)」が来るのかのスコアを確率として表現されるように変換しています。
また、日本国内の事例として注目したいのが、弊社澁谷によってリリースされた日本語特化のガードレールモデルです。 LLMへの危険な入力を検出する日本語に特化したガードレールモデルを開発し、国内初のオープンソース化しました
グローバルなモデル(Llama Guardなど)は英語のデータセットが中心であるため、どうしても日本語特有の言い回しや、文化的なコンテキストを含んだコンテンツの検知精度が落ちる傾向にあります。結果、日本語データセットにおいて、ShieldGemma やGPT-4o を超える精度で危険性を判別ができることを確認しています。
分類型ガードレールモデルのメリット・デメリットをまとめます。
| メリット | デメリット |
| ・高速: 推論にかかる時間をモデルサイズによって早くすることが可能。チャットボットのようなリアルタイム性が求められるUIでも体験を損なわない。 ・低コスト: CPUインスタンスでも十分に動作するため、GPUリソースをLLM本体に集中させることができる。 |
・文脈(Context)に弱い: 例えば「推理小説の中で、犯人が完全犯罪を企てるシーン」を書かせようとした場合、単純な分類器は「犯罪の助長」として誤検知してしまう可能性があります。前後の文脈や「これはフィクションである」という前提を理解するのが苦手。 ・説明性がない: 「なぜ違反なのか?」という理由をユーザーに提示したり、開発者がデバッグしたりするのが困難。 |
新しい潮流:推論型ガードレール
ここで登場するのが「推論型」のガードレールです。本記事で取り上げる GPT-OSS Safeguardがこれに該当します。
これは分類タスクを、LLM自体が持つ「指示従順性(Instruction Following)」と「文脈理解能力」を活用し、自然言語で記述されたポリシーに基づいて動的に判定を行うアプローチです。
汎用的なLLM(あるいは指示チューニングされたモデル)に対し、システムプロンプトとして①安全性ポリシーと②判定対象のテキストを入力し、思考プロセス(Chain-of-Thought)を含めた判定を行わせる。
- 入力:
[Policy Definition] + [Input Text] + [Instruction: Is this safe?] - 判定ロジック: LLMは入力されたポリシーをその場で解釈し、文脈を考慮した上で
Safe/Unsafeの判断と、その根拠を出力する。
Chain-of-Thoughを内部的に持っているため、いきなり「これは有害」と判別するのではなく人のように順を追って判断します。この「思考プロセス」が入ることで、判断の精度と柔軟性が劇的に向上します。
例)
- 入力の意図を解釈する。「ユーザーは化学実験の手順を聞いている」
- ポリシーと照らし合わせる。「ポリシーでは危険物の製造法は禁止されている」
- 文脈を確認する。「しかし、これは高校の理科の授業範囲内であり、危険な爆発物の製造ではない」
- ポリシーに違反しているか結論を出す。「Safe」
GPT-OSS Safeguardについて
GPT-OSS Safeguardの詳細も見ていきましょう。
GPT-OSS Safeguardは、OpenAIが2025年10月末にリリースした、安全性分類タスクに特化したオープンウェイト推論モデルです。2つのサイズで提供されています。
- gpt-oss-safeguard-120b: 117Bパラメータ(5.1Bアクティブパラメータ)
- gpt-oss-safeguard-20b: 21Bパラメータ(3.6Bアクティブパラメータ)
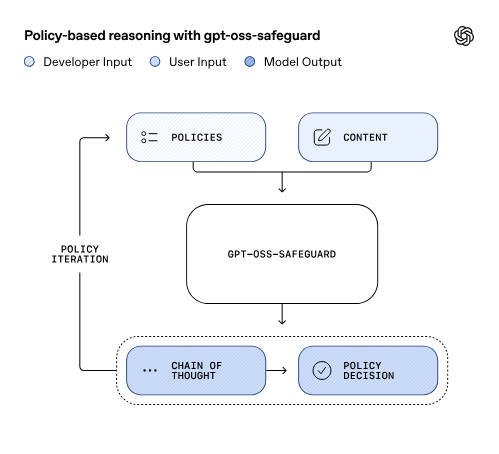
図:OpenAI introducing-gpt-oss-safeguardより
主な特徴
- ポリシーベースの推論
- 開発者が提供したポリシー(安全性ガイドライン)を推論時に直接解釈し、それに基づいてコンテンツを分類します。これは従来の事前学習済み分類モデルとは異なり、ポリシーを柔軟に変更できる点が大きな特徴です。
- Chain-of-Thought(思考連鎖)による透明性
- モデルがどのように判断に至ったかを示す推論プロセスが可視化されます。これにより、監査可能性と説明責任が確保されます。
- Harmonyレスポンスフォーマット
- 専用の構造化プロンプトインターフェースを使用し、以下の2つのチャンネルで応答を分離します。これによって長い推論に処理がブロックされ、判別の応答が得られないというUXの課題を解決します。
- Reasoningチャンネル: ポリシーを通じた推論、エッジケースの考慮、ロジックの説明
- Outputチャンネル: 指定された形式での分類決定
- 専用の構造化プロンプトインターフェースを使用し、以下の2つのチャンネルで応答を分離します。これによって長い推論に処理がブロックされ、判別の応答が得られないというUXの課題を解決します。
アーキテクチャ
GPT-OSSモデルを安全性判別タスクへファインチューニングしたもので、Mixture-of-Experts (MoE)アーキテクチャを採用しています。そのGPT-OSS自体が、MoE重みをMXFP4量子化されており、非常に軽くなっています。GPT-OSS Safeguardも同様に量子化済であり、20Bモデルだと通常40GBほどのVRAMを要するところ、16GBほどのVRAMでもモデルをGPUに乗せることができます。
openai/gpt-oss-safeguard-20b · Hugging Face
openai/gpt-oss-20b · Hugging Face
推論型ガードレールモデルのメリット・デメリットをまとめます。
| メリット | メリット |
|
・圧倒的な文脈理解: 皮肉、ユーモア、メタファー、そして複雑な「役割演技(ロールプレイ)」の文脈を理解できる。 ・カスタマイズ性: 再学習(Fine-tuning)をしなくても、プロンプト(System Prompt)を書き換えるだけで、「競合他社の話は禁止」「投資助言は禁止」といった独自のルールを追加できる。 ・説明性 (Explainability): なぜブロックしたのか、その理由が出力されるため、透明性が高い。 |
・遅い: LLMの生成プロセス(デコード)が走るため、数百ミリ秒〜数秒のレイテンシが発生。 ・リソース消費: 推論のために多くのGPUメモリ(VRAM)を消費する。サービス提供用のLLMとは別に、ガードレール用のGPUを用意する必要があるかもしれません。 |
使い分けの基準:どちらを選ぶべきか?
「分類型」と「推論型」。どちらが優れているかという話ではなく、適材適所です。
| 従来型(分類型)を選ぶべき場合 | 推論型を選ぶべき場合 |
|
✓ ポリシーが安定しており、頻繁な変更がない ✓ レイテンシが critical(リアルタイム処理) ✓ 計算リソースが限られている ✓ 特定ドメインで大量の高品質ラベル付きデータがある ✓ 本番環境での安定性・一貫性を重視 |
✓ ポリシーが頻繁に変更・更新される ✓ 新しいリスクや未知の脅威への対応が必要 ✓ 高度な文脈理解やニュアンスが重要 ✓ 説明可能性・監査性が求められる ✓ ラベル付きデータの収集が困難 ✓ 複数ポリシーの同時評価が必要 |
実務的には、これらを組み合わせるハイブリッド構成が最も現実的な解になります。
まず、前段に軽量な分類型モデル(またはRegexのような単純なフィルタ)を配置し、明らかな違反を高速に弾きます。ここで9割のスパムや攻撃を防ぎます。 そして、そこを通過したグレーゾーンの入力や、最終的なLLMの回答出力に対してのみ、重厚な推論型モデルを通してチェックを行う方策です。
実際にGPT-OSS Safeguardのテクニカルレポートでも、次のように明言されています。
gpt-oss-safeguard can be time and compute-intensive, which makes it challenging to scale across all platform content. Internally, we handle this in several ways with Safety Reasoner: (1) we use smaller and faster classifiers to determine which content to assess and (2) in some circumstances, we use Safety Reasoner asynchronously to provide a low-latency user experience while maintaining the ability to intervene if we detect unsafe content.
(日本語訳)
gpt-oss-safeguardは、処理時間と計算リソースを大量に消費するため、プラットフォーム上のすべてのコンテンツに対して大規模に適用(スケール)することは困難です。そこで我々は内部的に、「Safety Reasoner」を用いて以下のいくつかの方法でこの課題に対処しています。(1) 事前フィルタリング: より軽量で高速な分類モデルを使用し、(重いモデルで)詳細に評価すべきコンテンツを選別しています。(2) 非同期処理: 状況によっては、Safety Reasonerを非同期(バックグラウンド)で実行します。これにより、ユーザーには遅延の少ない快適な体験を提供しつつ、もし安全でないコンテンツが検知された場合には、後から介入(削除や停止など)できる体制を維持しています。
まとめ
本記事では、生成AIの社会実装に不可欠なガードレールモデルについて、主流である分類型と新たな潮流である推論型の特性、メリット・デメリット、そして使い分けの基準までを解説しました。
主要なポイントは以下の通りです。
- ガードレールモデルの役割: LLMへの入力と出力の両方を監視し、有害なコンテンツやポリシー違反を防ぐことで、AI利用の安全性を担保します。
- 分類型ガードレール
- 事前に学習したパターンに基づいてコンテンツを機械的に分類します。
- メリット: 高速で低コスト。リアルタイム処理やリソースが限られた環境に適しています。
- デメリット: 文脈理解が苦手で誤検知のリスクがあり、なぜブロックされたかの説明性に欠けます。
- 推論型ガードレール
- LLMが与えられたポリシーを動的に解釈し、論理的な思考プロセスを経て文脈を考慮して判定します。
- メリット: 圧倒的な文脈理解力とカスタマイズ性、そして説明性の高さが特徴です。OpenAIのGPT-OSS Safeguardが代表例です。
- デメリット: LLMの推論に時間がかかり、多くの計算リソースを消費します。
- ハイブリッド構成の重要性
- どちらか一方が優れているわけではなく、それぞれの長所を活かした分類型と推論型のハイブリッド構成が最も現実的かつ効果的なアプローチです。
- 軽量な分類型で大部分を高速にフィルタリングし、複雑なケースや最終出力のみを推論型で詳細にチェックすることで、速度と精度のバランスを取ります。
生成AIの活用が進む中で、安全性確保は避けて通れないテーマです。本記事が、ガードレールモデルの理解を深め、皆様のAIプロダクトにおける安全なシステム設計の一助となれば幸いです。
なお後続記事では、推論型の代表格であるGPT-OSS Safeguardの実践的な検証結果をまとめます。本記事の内容を引き継いで、実際に推論型のガードレールモデルを利用する際の勘所を紹介いたします。合わせてお読みいただけますと幸いです。
参考


