MCP サーバー開発 Tips — エージェントを本番戦力に
 この記事をシェアする
この記事をシェアする



ARISE analyticsの挺屋です。私は社内の生成AI活用推進を担当し、日々の開発現場でAIツールをどのように安全かつ効果的に使うかを検証・標準化しています。本記事では、その取り組みの中で得られたMCPサーバーのツール作成について、実践的な知見をまとめます。
この記事は、次の方を想定しています。
-
企業内でMCP サーバーを設計・実装し、提供したいエンジニア
-
MCP実装をしているが、ツールの利用の制御がうまくいっていない方
以下、背景と価値、仕組みのさわりを述べた後、実装と運用に効くTipsを体系的に解説します。
企業でのMCP開発の必要性
企業でAIツールを利用したり、エージェント活用をする際には、MCPを利用することが重要だと思います。MCPで各種外部ツールにAIがアクセスできるようにすることで、真の業務効率化がされると感じています。むしろ、それが無い状態ではいつまでもAIとの対話による問題解決にとどまり、AIが作成した文章やコードをコピペしたり、教えてくれた手順を人が実行するなどAIエージェントにタスクを任せることがしにくくなります。
しかし、企業ではAIの利用に対してある程度ガバナンスを担保して利用を進めることが求められます。ARISE analytics(以下ARISE)でもAIに対する利用ガバナンスの是正がすべからく行われています。ガバナンスを満たしつつ、MCPでの外部接続をした活用を進めるにあたっては、MCP サーバーを自作して、次のような2つの利点を得ることができます。
カスタム機能の実現
-
企業ごとに独自開発した社内システムや業務プロセスに、AI エージェントを直接接続できます。例えば、自社の勤怠管理システム、社内申請ワークフロー、独自開発のCRM など、既存の公開MCPサーバーではカバーできない社内サービスとの連携が可能になります。
セキュリティとプライバシーの制御
-
既存の公開MCPサーバーでは、企業のセキュリティポリシーや社内利用基準を満たさないケースがあります。例えば、認証方式、ログ保管要件、データの外部送信制限などが要件を満たさず、利用を許可できないことも少なくありません。自社でMCPサーバーをホストすることで、最小権限の原則、短命トークン、レート制限、スロットリング、出力検証、人手承認(HITL)といった防御層を、企業の要件に合わせて実装できます。プロンプトインジェクションは原理的にゼロにできないため、出力検証と権限制御で"外側"から守る設計が、企業では決定打になります。
MCPの仕組み
次にMCPサーバーを開発するうえで理解するべき基本的な概念を紹介します。
MCP(Model Context Protocol) は、LLMエージェントが外部のツールやシステムを連携するための標準的なプロトコルのことをいいます。MCPは、AIツール(Claude、Cursor、VS Codeなど)と外部システム(データベース、API、ファイルシステムなど)間の複雑な連携を簡素化し、AIアプリケーションの可能性を広げる重要な仕組みとして位置づけられています。
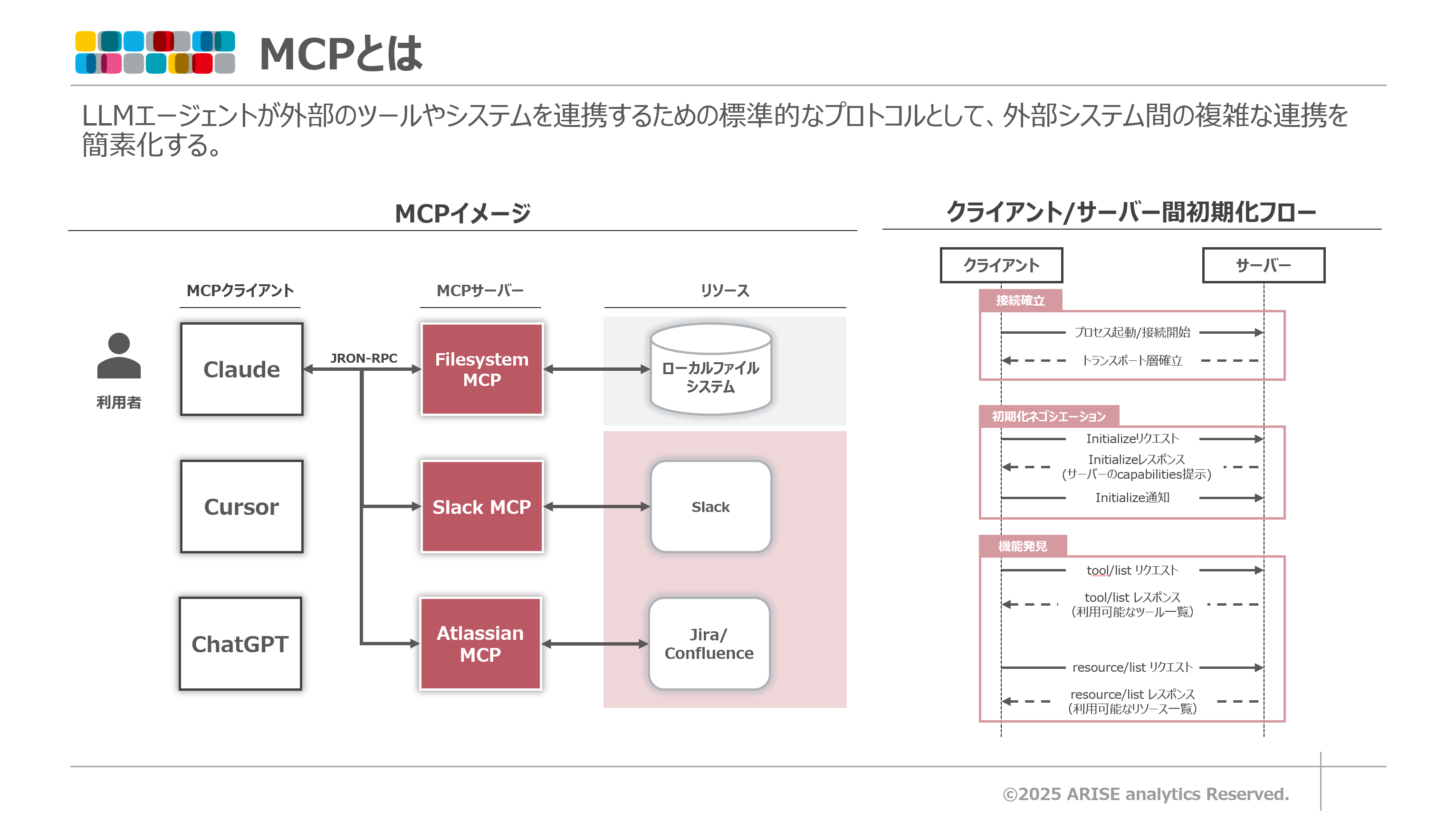
MCPはクライアント・サーバー型アーキテクチャを採用しており、以下の構成要素で成り立っており、MCPクライアント(CursorやClaude Desktopなど)・MCP サーバー間で、JSON-RPC 2.0 に基づくメッセージをやり取りします。やり取りのトランスポートはstdioやStreamable HTTPに対応しており、MCPサーバーはローカル/リモートどちらでも可能です。サーバーが公開する「ツール(Tools)」「リソース(Resources)」「プロンプト(Prompts)」を通じて、外部の機能やデータに安全にアクセスします。MCPサーバー開発する際は主にツールにどのような挙動をさせたいか詳細を実装していくことになります。
サーバーは起動時に能力(capabilities)を提示し、クライアントは tools/list / resources/list で一覧を取得、必要に応じて call_tool でツールを実行します。つまりクライアント側は一覧を取得したテキストを読み取り、どんなMCPツールを利用できるのかを理解する必要があります。
なぜツール設計が重要なのか
上記の仕組みで重要なのが、“LLMにとってのMCPの仕様書はテキスト(説明)とスキーマだけ”という事実です。人間がAPIの仕様を理解する際のように察してはくれないため、名前・説明・入力スキーマ(JSON Schema)を厳格かつ具体的に整えるほど、ツールの誤用が減ります。
通常のAPI開発では関数に対してどのような引数を渡せばよいかが明確であり決定論的システムなので、そのツールの利用方法は明確です。しかし、MCPツールは自然言語の指示で呼び出されるため、どのようにツールを利用するのかが明確でない非決定論的システムとなります。そのため、しばしばLLMがツールを誤用することは起こります。
例えばエージェントに対して「今日は傘を持っていくべき?」という質問をしても、エージェントの挙動は決定論的ではなく、以下のような様々な戦略をとる可能性があり決定論的ではありません。
-
天気ツールを呼び出して判断する
-
一般知識から回答する
-
「どこの天気ですか?」と逆に質問する
-
場合によっては、ツールの使い方を誤解する
この非決定論性により、ツール設計の考え方を根本から変える必要があります。
また、ツールを使うのはエージェントでありLLMです。LLMでは一度に扱えるコンテキストの量が有限です。そのためツールを使う・返答を理解するためには所定のコンテキストの範囲内で行う必要があります。たとえコンテキストの範囲内に収まっていても処理に必要なコアの情報が何なのかよくわかりにくいものが返ってくると、ユーザーが本来望んでいるエージェントの挙動とは異なった動きをすることがあります。例えば人間同士の会話でも、得たい回答に対して長ったらしくて何が結論なのかわからない内容で答えられたときに、「で、なにが言いたいのですか?」と心の中で言いたくなると思います。そういったところにも注意を払ってツールを設計・実装していく必要があります。
以降のTipsは、この「LLMという扱えるコンテキストが有限かつ、確率的ユーザーのためのAPI設計」を徹底するための具体的な作法をいくつか紹介します。
ツール設計Tips
本記事ではMCPサーバーを実装するうえで、気を付けておいた方がよいTipsを5つ紹介します。各Tipsの概要は次の通りです。
-
一覧取得をやめて検索をレスポンスするようにして、トークンの消費を削減
-
ツールの説明文を丁寧に記述することで、エージェントが正しくそのツールを使えるようにする
-
レスポンスの形式を工夫することで、トークン消費を削減
-
ツールの呼び出し回数が少なくなる設計をして、エージェントの応答時間の効率を良くする
-
エラーの内容をエージェントが理解しやすいようにすることで、エージェント自身によるタスク継続を促す
各Tipsには実装サンプルを載せていますが、ここでは仮の題材として社内の図書システムとの接続MCPを作成することを挙げています。その図書システムからはARISEにある技術書などの書籍を借りることができます。どのような書籍があり、各書籍がどのようなステータスを持つのかなどMCPサーバー化できる余地があるためここで取り扱うこととします。なお、サンプル実装はあくまで仮でありそのようなMCPサーバーがARISE内で動いているわけではありません。
1 )「一覧」を捨て「検索」を実装し、トークン消費を削減する
初期実装で起こりうる問題
既存のシステムのAPIコールをMCPのツールとして実装しようとしたとき、良く起こりがちなのは既存のAPIエンドポイントをそのまま何も考えずラップしたツールを作成することです。ラップすること自体が悪いわけではありませんが、何かの一覧の取得などAPIレスポンスが多くの文字数を取る場合に問題となります。
▼問題の実装例(例の提示のため、エラーハンドリングや認可など本来あるべき実装は省略します)
ここでは図書館で扱っているすべての書籍を取得するAPIを叩いています。
コンピュータのメモリは豊富ですが、LLMのコンテキストは限られています。
従来のプログラムなら、300冊のリストを効率的にループ処理できます。しかし、LLMエージェントは
-
トークン単位で全てを読む必要がある - 1冊ずつ、全ての情報を順番に処理
-
無関係な情報も消費する - 求めていない本の情報も全て読み込む
-
コンテキスト枠を圧迫する - 本当に必要な思考や推論のスペースが減る
という挙動をするため、レスポンスが長すぎるとLLMの有限なコンテキストの範囲内では処理しきれないケースが生じます。
推奨アプローチ
Anthropicのドキュメント「Writing effective tools for LLM agents」では、明確にこう述べています。
より多くのツールが常により良い結果をもたらすわけではありません。 一般的な誤りは、既存のソフトウェア機能やAPIエンドポイントを単純にラップしただけのツールを作ることです。エージェントには独自の「アフォーダンス(利用可能な行動の認識)」があり、従来のソフトウェアとは異なります。(和訳)
解決策としては無駄な一覧取得はやめ、なるべく検索のアプローチをとるようにすることです。
list_all_booksの代わりに検索ベースのツールを実装してみます。
このツールを使えば確実にLLMが扱える範囲内のコンテキストのみを処理することができるようになり、ツールの利用失敗を減らすことができます。
▼動作例
2 ) ツール説明を丁寧に書く
情報不足の問題
ツールの説明文が簡潔すぎる場合、人間にとっては十分かもしれませんが、エージェントにとっては不十分です。
このようなツールを使った場合以下のようなエージェントの挙動になることが考えられます。
人間の開発者がAPIドキュメントを読む場合、以下のような暗黙知を持っています。
-
IDは通常、検索結果やリストから取得する
-
ISBNコードは書籍の一意な識別子である
-
存在しないIDを渡すとエラーが返る
しかし、LLMエージェントはこれらの暗黙知を持っていません。そこで、明示的に説明する必要があります。「なぜツール設計が重要なのか」のセクションでも触れた通り、ツールをどのように使ったらよいのかエージェントに対してちゃんと説明するように丁寧に書くことを心掛けなければいけません。
推奨アプローチ
Anthropicのベストプラクティスガイドでは、こう推奨されています
ツールを使用する際に Claude から最高のパフォーマンスを引き出すには、次のガイドラインに従ってください。
非常に詳細な説明を記載してください。これはツールのパフォーマンスにおいて最も重要な要素です。説明には、ツールに関する以下の点を含め、あらゆる詳細を記載する必要があります。
ツールの機能
いつ使うべきか(そしていつ使うべきでないか)
各パラメータの意味とツールの動作への影響
ツール名が不明瞭な場合、ツールが返さない情報など、重要な注意事項や制限事項。ツールに関する詳細な情報をクロードに提供すればするほど、ツールをいつ、どのように使用するかをより正確に判断できるようになります。ツールの説明は1つにつき少なくとも3~4文、複雑なツールの場合はそれ以上の長さにすることを目標にしてください。
具体例よりも説明を優先しましょう。ツールの使い方の例を説明文やプロンプトに含めることは可能ですが、ツールの目的とパラメータを明確かつ包括的に説明することの方が重要です。具体例は、説明文を完全に書き終えてから追加しましょう。(和訳)
▼改善版のツール説明
ここではツールの概要や、引数、返り値や利用例、注意点などを網羅的に記載しています。これくらい書くことでツールの誤用を防ぐことができます。
実際にAnthropicがウェブ検索機能をリリースした際、Claudeが検索クエリに不要な「2025」という年号を自動的に追加していたという問題が見つかり、それに対してツールの説明文を改善することでこのバグを解消したという例がありました。
このように、ツールの動作を決めるのはコードだけではなく、ツールの説明文やパラメータ定義が、エージェントの振る舞いを大きく左右します。
3 ) レスポンスの情報量を適切な量にする
エージェントへの情報過多レスポンス問題
バックエンドAPIが返す全てのフィールドをそのままエージェントに返している場合、そのうちの多くの情報は不要なもので、無駄にトークン消費することになります。
例として、とある本の詳細項目を知りたいときにget_book_detailsツールを使ったと考えます。
▼すべてのフィールドを返すレスポンス例
このレスポンスの問題点として以下のことが挙げられます。
-
トークンの無駄遣い: 1冊の情報だけで約800トークン消費
-
認知負荷が高い: エージェントが必要な情報を探すのに時間がかかる
-
技術的詳細の過剰: width、height、barcodeなどは通常不要
-
読みにくい: ISO形式の日時、内部ID、システムメタデータなど
推奨アプローチ①
エージェントにしてほしいタスクに対して必要な情報のみに選別して返すようにしましょう。
処理に対して不必要であるものを返さないのはもちろんですが、自然言語で理解できないものも返さないようにするべきです。
例えば、titleやauthorなどは自然言語として理解しやすいものですが、uuidなどの低レベルの識別子は本の詳細情報として返してもどんな特性のものなのか理解できない(そのような情報ではない)ので返すべきではありません。もちろん、このMCPを使用するユースケースとして後続に本の予約をするときにこのuuidを利用するのであれば、返した方が良さそうです。ここではあくまで本の詳細を理解するのにはuuidの情報は意味をなさないということを言っています。
推奨アプローチ②
アプローチ例としてはresponse_formatパラメータを導入することが1つ手として考えられます。
GraphQLのように、エージェントが必要な情報の粒度を選択できるようにします。
▼response_format導入例
ここでは簡潔モード(concise)と詳細モード(detailed)を用意し、レスポンスの情報量を切り替えれるようにしています。
conciseレスポンス例
detailedレスポンス例
各レスポンス例を見てとれるように、レスポンスの内容を読むのに必要なコンテキストサイズがまるで異なります。本の貸し出しのときには本の詳細を提示しないといけないかな、逆に検索に付随する付加情報の提示であれば簡潔モードでもいいかなといったようにユースケースによって粒度の調整ができると、ユーザビリティが向上してとても良い設計になります。
▼実際の使用例
4 ) ツールを1つに短縮し、応答時間を短縮する
ツールが過度に細分化される問題
「単一責任の原則」に従い、機能ごとに細かくツールを定義した場合を考えます。ここでは本を貸し出し・までに必要そうなツールを列挙してみます。
一見きれいに分割されて見えます。しかし実際にエージェントが使うとツールの呼び出しが非効率になることが起こり得ます。
▼非効率な呼び出し例: シナリオ:「機械学習の本で今借りられるものを探して、関連書籍も教えて」
ここでは、借りられる本を探し当てるのに7回ものツールレスポンスが生じて、そのたびにレスポンスをLLMが理解し次の打ち手を考え、ツールの呼び出しをすることを繰り返します。時間的にも非効率ですし、毎回LLMのトークン消費があるのでコスト的にも非効率となります。
推奨アプローチ
機能を統合し、内部で複数の個別操作(またはAPI呼び出し)を処理するよう、ツールを1つにまとめることができます。
Anthropicのガイドラインでもこの方法が紹介されており、そこでは具体例として次のように説明されています。
(会議を設定するとき)list_users、list_events、create_eventを実装する代わりに、空き時間を見つけてイベントをスケジュールするschedule_eventを検討してください
(ログ情報を返すとき)read_logsを実装する代わりに、関連するログ行とその周辺コンテキストのみを返すsearch_logsを検討してください
(顧客の関連情報を返すとき)get_customer_by_id、list_transactions、list_notesを実装する代わりに、顧客の最近の関連情報を一度にまとめるget_customer_contextを実装してください(和訳)
その方法に従って、借りされる本はあるか検索するツールを次のように統合して実装することができます。
ここではユーザーが検索したい観点での書籍の検索と、借りられるかのチェック、関連書籍の確認を全部一度に行い、逐次的なレスポンスはしないようにしています。そうすることで次のような動作になり効率化を図れます。
5 ) エラーを「ガイド付き代替案」に変える
無意味なエラーメッセージ問題
本を借りるための関数を次のように書いてエラーを吐き出すことを考えてみます。
ここでは本が見つからなければNot Found、貸出できなければNot availableがエラーメッセージとして返されます。しかしこの情報でユーザーがエージェントに期待する挙動を十分に満たせるでしょうか。おそらく次のようなユーザーの声が上がると思います。
単純なエラーレスポンスにしたばかりに、ユーザーは本を借りたいという要求に対してそれを満たす挙動が無く、現状の確認だけに終わってしまっています。もちろん本の詳細を確認するツールを、別途ユーザーがこの後に呼び出すよう指示すればよいのですが、いちいち挙動をユーザーに任せてしまっていては体験が非常に悪くなります。もしかしたらユーザーはここで離脱するかもしれません。実装したいMCPサーバーが何かしらのECサイトの購入補助だとしたら、購入を阻害する機会損失にもなるかもしれません。
推奨アプローチ
エラーメッセージを単なる失敗の通知だけに終わらせず、次の動作のヒントを提示することが重要です。
-
診断情報: なぜ失敗したのか
-
指針: 次回どうすれば成功するか
-
代替案: 今すぐ取れる別の行動
Anthropicのガイドラインでも次のように示されています。
ツール呼び出しがエラーを起こした場合(例:入力検証時)、不透明なエラーコードやトレースバックではなく、具体的で実行可能な改善を明確に伝えるようにエラーレスポンスをプロンプトエンジニアリングできます。(和訳)
▼エラーメッセージ改良例
書籍の存在確認では、見つからなかった事象に対してタイトルが違うかもしれないので再度検索しなおした方がよいという指針、実はこのタイトルなのではないかという代替案を提示することで、次にエージェントはどのような条件でリトライ処理をすればよいか明確になります。
▼存在確認の改善例
在庫の確認では、在庫が無かった時に対して関連のあるこれらの本なら借りられるよという代替案を示すことで、ユーザーの離脱なく借りたいという要求に対してダイレクトに答えることができます。
▼在庫確認の改善例
実際に設計していくにあたってこのような表を作成して整理していくとよいでしょう。
|
エラータイプ |
必須情報 |
推奨代替案 |
追加提供すべき情報 |
|---|---|---|---|
|
book_not_found |
類似タイトル3件 |
search_books()の使い方 |
購入リクエスト方法 |
|
not_available |
返却予定日、借主情報 |
予約、代替書籍、借主連絡 |
類似書籍2-3件 |
|
invalid_category |
有効なカテゴリ一覧 |
最も近いカテゴリ名 |
カテゴリ取得ツールの案内 |
|
invalid_parameter |
パラメータの説明 |
正しい形式の例 |
よくある間違いリスト |
|
permission_denied |
必要な権限 |
権限リクエスト方法 |
代替手段(代理依頼など) |
|
already_borrowed |
現在の貸出情報 |
延長方法 |
返却期限リマインダー |
まとめ
MCPのツールを実装するにあたって、トークン削減やより確度の高い実行のための注意点を説明しました。
MCPサーバー開発によって会社での生成AI活用をより一層高度なものにすることができると思います。その際にユーザビリティを意識して、使いやすいものを展開する必要がありますが、そのために何をすればよいか上記を参考にして作っていただけたら幸いです。
ここでは設計にフォーカスをしており、実装の過程での注意点はあげていません。実装するにあたって、細かなテストサイクルを用意し、そのテスト観点の整備・テストの実装・修正プランニングもLLMに任せてみて、AIのためのツール開発をAIにさせてみるのも良いでしょう。その際には実装観点のコンテキストに本記事の内容を入れてみると良いかもしれません。
ARISEでは生成AI活用を積極的に行っています。これからも生成AIについての記事を更新していきますので是非ご注目ください。
参考


