LLM時代のデータ管理
 この記事をシェアする
この記事をシェアする



はじめに
生成AI技術の急速な発展により、データ分析業務の様相が大きく変化しています。ChatGPTをはじめとするLLM(大規模言語モデル)は、データの可視化、統計分析、仮説検証、モデリングといった従来人間が行ってきた分析作業を支援し、自動化しつつあります[1][2]。
しかし、LLMが真に分析業務で価値を発揮するためには、質の高いデータが不可欠です。
人間の分析者は、データを見たときにドメイン知識を持っているため、業界特有の慣習、組織固有の定義、暗黙のビジネスルール——「この数値はおかしい」「この欠損にはこういう背景がある」「このカラムは実際にはXXを意味している」といった判断が可能です。一方、LLMは公開データ(Web)で訓練されており、組織固有のドメイン知識を持ちません。その結果、適切にガバナンスされ、構造化され、メタデータが整備されたデータでなければ、LLMも正確で意味のある分析結果を生成できません。むしろ、不適切なデータ基盤の上では誤解を招く結果を量産する危険性すらあります。
本記事では、LLMによる分析業務自動化を実現するためのデータ管理戦略を整理します。
1章:LLM-Readyなデータ管理
データ管理の体系的なフレームワークを理解する上では、DMBOK(Data Management Body of Knowledge)[3]を引用するのが良いでしょう。
DMBOKでは、適切なデータ管理を行う上で必要な10の知識領域を定義しています。これらの領域は相互に連携し、組織全体のデータ資産価値を最大化する包括的なエコシステムを形成すると主張しています。
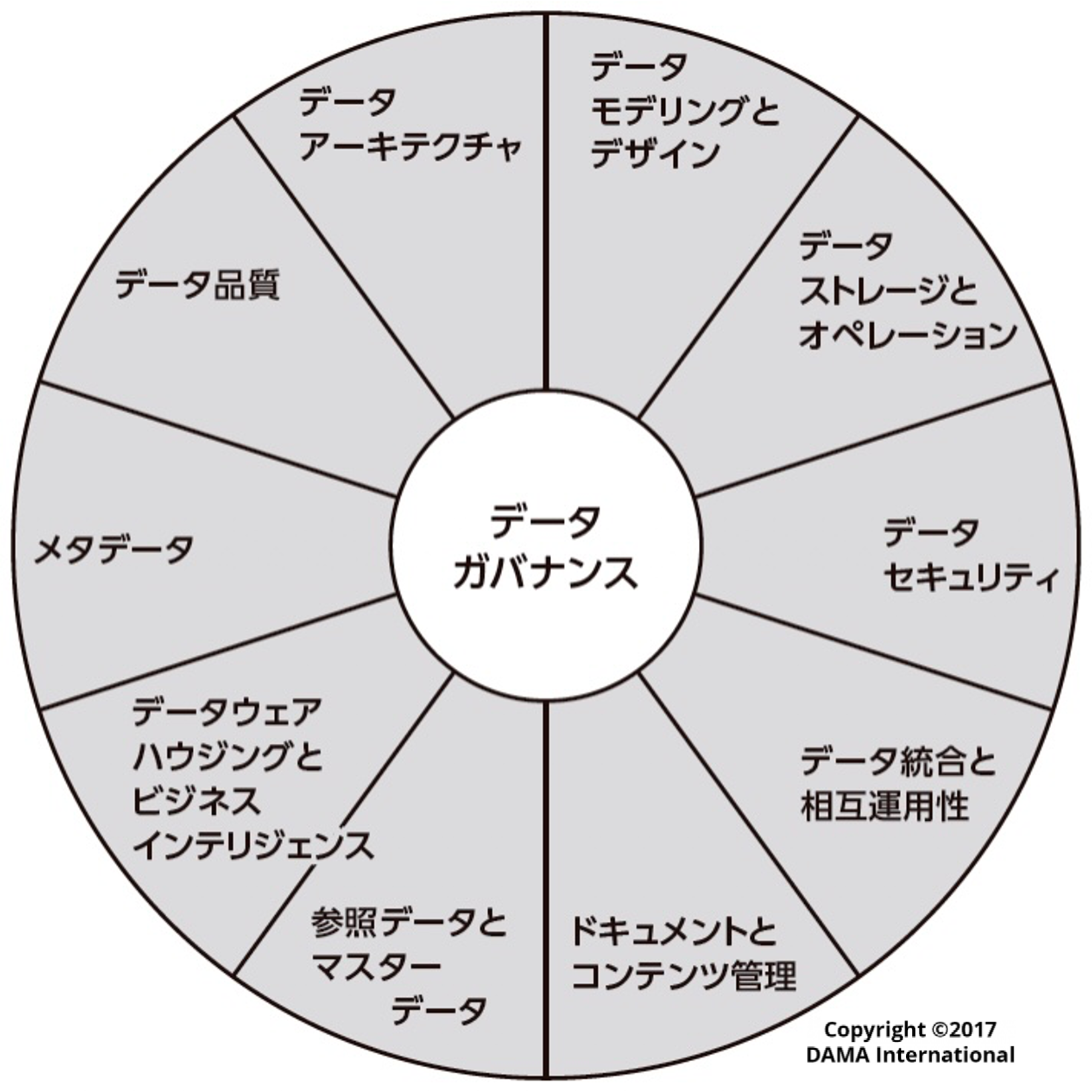
出所:『データマネジメント知識体系ガイド 第二版』 DAMA International編著、DAMA日本支部、Metafindコンサルティング株式会社 監訳、日経BP
全ての知識領域が重要ではありますが、特にLLMでのデータ分析自動化を目指すうえでは以下の課題解決が特に重要となります。
-
課題1:データ品質の検証困難
-
LLMは品質の低いデータに基づいて一見もっともらしい分析結果を生成してしまいます。従来の分析では人間の直感やドメイン知識でフィルタリングできていた異常値や偏りも、LLMの流暢な説明により見過ごされるリスクが高まり、従来から存在するGIGO(Garbage In, Garbage Out)問題がより深刻化しています。
-
-
課題2:データコンテキストの欠如
-
LLMによる分析プロセスにおいて、どのデータがどのように分析結果に影響したかの追跡が困難です。データの系譜や変換履歴、ビジネスコンテキストが不明瞭だと、LLMが文脈の無視、勝手な変数定義の補完をすることで誤った分析を行い、信頼性のある分析や改善が不可能になります。
-
-
課題3:処理構造の複雑化による変更対応の困難
-
リアルタイムで変化するデータ環境において、複雑化した処理構造のため定義変更や仕様変更を迅速に反映できません。LLMが古い前提や変更前の定義に基づいて分析を続けることで、時間とともに分析精度が劣化する問題が発生します。
-
実際、AWSの2024年レポートではCDOの93%がデータ戦略をLLMの価値創出に重要と回答する一方、実用化率は7%に留まっており、これは効果的なデータ管理の不備が主要な阻害要因となっていることを示しています[4]。
これらの課題を踏まえ、本稿では特にLLM活用の上で重要な、以下の三領域に焦点を当てて議論を進めます。
-
①データモデリング+データアーキテクチャ:効率的で段階的な品質向上を実現するデータ設計
-
②メタデータ:LLMがデータを正しく理解し適切なコンテキストで分析するためのメタデータ管理
-
③データ品質:LLMの高い処理能力を活かすための自動化された継続的なデータ品質管理
2章:データ設計(Data Architecture & Modeling)
①LLM時代におけるデータモデリングの重要性
売上を集計しようとしたら、事業部ごとに異なるテーブルが存在し比較できなかった。あるいは、分析に使ったテーブルが実は移行前の古いものや中間テーブルだった——こうした問題に心当たりはないでしょうか。
データ設計の不備は従来から課題でしたが、LLMによる自動分析においてはその影響がさらに深刻化します。
-
概念の分散:同一の概念(例:顧客、売上)が複数のテーブルに異なる名称・構造で存在すると、LLMが適切なテーブルを選択できない
-
スキーマの複雑性:多段のJOINやネストしたクエリが必要な構造では、LLMの生成精度が低下する
-
スキーマの非記述性:
col1やtmp_customer_202301のような非直感的な命名は、LLMの正しいマッピングを妨げる -
処理順序の非構造化:データ変換の流れが整理されていないと、LLMがどの段階のデータを参照すべきか判断できず、古いテーブルや中間生成物を誤って参照する
これらの課題は、組織やシステムの成長に伴い、場当たり的にテーブルやパイプラインが追加されてきた結果として生じます。事業部ごとに独自のテーブルを作成した、システム移行時に旧テーブルを削除せず残した、一時的な分析用テーブルがそのまま定着した——こうした個別最適の積み重ねが、全体としての一貫性を失わせています。
この状態を解消するには、LLMが迷わず正しいデータを参照できるよう、データ基盤を整理する必要があります。「顧客」「売上」といったビジネス概念ごとに参照すべきテーブルが一意に定まり、テーブル名や配置場所から「生データなのか、加工済みなのか、分析用に最適化されたものなのか」が判別できる——そのような構造が求められます。
これを実現するのが、階層的なデータ処理アーキテクチャと、構造を明確化するデータモデリング手法です。次節でその具体的なアプローチを解説します。
②主要なデータ設計手法とLLM時代での活用
データ処理アーキテクチャ
「データ品質の段階的・漸進的向上」のために、データ処理を明確な階層構造とすることが推奨されています[5]。生データをいきなり分析可能な形に変換するのではなく、メダリオンアーキテクチャのような生データ取得⇒クリーニング⇒特徴量生成といった処理を段階をわけることでエラーの早期発見と修正が可能になります。
さらに、「責任分離による管理容易性・保守性の確保」 も重要な要因です[6]。各層での処理を独立化することで、エラーが発生した際の影響範囲を特定しやすくなり、必要な部分だけを再実行できます。これにより、データエンジニアとアナリストなどチーム間での役割分担も明確になります。
また、上流のデータ変更が下流に与える影響を段階的に制御できるため、システム全体の安定性が向上します。このような階層的処理アプローチを実現するため、業界では複数のアーキテクチャパターンが提案されています。
|
処理段階 |
概要 |
Medallion |
Kedro Layered |
DWH |
Data Lake |
|---|---|---|---|---|---|
|
生データ取込 |
外部ソースから取得した生データをそのまま保存する。 基本的には処理を行わないが、セキュリティ上の加工(マスキング等)処理は実施する。 |
Bronze |
01_raw |
Source Systems |
Raw Zone |
|
スキーマ・欠損処理 |
生データに対して、クリーニング・型変換などの初期処理を行う。 |
Bronze |
02_intermediate |
Staging |
Processed Zone |
|
データ統合・変数整備 |
ドメイン固有のデータモデルに適合するように意味のあるデータの加工・生成等を行う。 |
Silver |
03_primary |
ODS |
Curated Zone |
|
特徴量生成 |
AI/BIで利用する特徴量データを作成する。 |
Gold |
04_feature |
Data Warehouse |
Curated Zone |
|
AI/BI |
モデリングや可視化を実施した結果や実行中の成果物を作成する。 |
- |
05_model_input〜07_model_output |
Data Marts |
Consumption Zone |
データモデリング
階層アーキテクチャとは別に、各層でどのような構造でテーブルを整理しておくかという観点を考える必要が存在し、それがデータモデリングになります。Silver層におけるデータモデリングは拡張性や長期保存のしやすさなど、源泉データ側の変更に柔軟な対応を目的とした構造が望ましいとされ、従来の第2・第3正規化(2NF, 3NF)やそこから拡張したData Vaultなどが現在では主流です。一方Gold層では、LLMや人間による検索・集計・分析の効率化を目的とした構造が望まれ、全てのデータを一つのTableに集約することでJOINを不要にしたOBT(One Big Table)やデータの重複を削減することで複雑な集計の計算ミスを抑えられるよう構造を明確化したスタースキーマが近年では多く見られます。
ここでは、主にLLMが直接利用するGold層におけるデータモデリング手法であるスタースキーマとOBTについての違いを整理します。
スタースキーマ
スタースキーマは、中央にファクトテーブル(売上金額、数量などの数値データ)、その周囲にディメンションテーブル(顧客、商品、日付などの記述的属性)を配置する構造です。

出所:『Understanding Star Schema』Databricks
1990年代にRalph Kimballによって提唱され、分析クエリの特性——集計、フィルタリング、グルーピング——に最適化されています。 この構造が有効な理由は、JOIN関係が単純化されることにあります。ファクトテーブルを中心とした1対多の関係が明確・各テーブル内でのデータ重複が存在しないため、LLMがテーブル間の関係を理解しやすく、適切なクエリを生成しやすくなります。また、BIツールとの親和性が高く、履歴管理(Slowly Changing Dimensions)にも対応できる柔軟性を持ちます。 一方で、JOINが必要になるため、テーブル数が増えるとクエリが複雑化する可能性があります。
事例として、BASEではスタースキーマを採用した分析基盤でLLMによるSQL自動生成を実現しています[7]。
OBT(One Big Table)
OBTは、スタースキーマと違い全ての関連データを1つのテーブルに事前結合・非正規化する手法です。この手法が生まれた背景には、クラウドデータウェアハウスの進化があります。ストレージコストが大幅に低下し、カラム型ストレージ(Parquet、ORCなど)が普及したことで、データの冗長性を許容してもクエリ性能を優先する設計が現実的になりました。Fivetranの検証では、OBTはスタースキーマと比較して10〜45%のクエリ性能向上が報告されています[27]。 OBTの最大の利点は、JOINが不要になることです。LLMは単一テーブルからのSELECTのみで分析を完結でき、複雑なJOIN生成によるエラーを回避できます。特にIoTデータやログシステムなど、大量のレコードを単純なフィルタリングで分析するユースケースに適しています。 一方で、データの冗長性が高くなるため、ディメンションの変更(例:顧客の住所変更)を履歴管理する場合は設計が複雑になります。また、スキーマ変更時には全データのバックフィルが必要になる場合があります。このため、OBTはSingle Source of Truthとしてではなく、分析用の最適化レイヤーとして位置づけるのが一般的です。
③ データ設計だけでは解決しない課題
ここまで、データ処理アーキテクチャによる階層化と、スタースキーマやOBTによるモデリングを解説してきました。これらの手法を組み合わせることで、データの所在が明確になり、LLMが参照すべきテーブルを判断しやすい構造を実現できます。 しかし、データ構造を整理しただけでは、LLMがデータを正しく理解できるとは限りません。例えば、スタースキーマで`revenue`というカラムを定義しても、それが「税込なのか税抜なのか」「返品を控除した後なのか」はLLMには分かりません。`customer`テーブルがあっても、「見込み客を含むのか」「解約済み顧客を含むのか」という定義は構造からは読み取れません。また、「売上 = 単価 × 数量 - 割引」といった計算ロジックも、スキーマ情報だけでは伝わりません。
これらを解決するために、データ層とLLMを接続するセマンティックレイヤ(データの意味づけを行う層)の重要性が語られています。dbt Labsも「セマンティックレイヤーはLLMとデータを接続する重要なインターフェースである」と述べています[10]。 つまり、データの「構造」に加えて、データの「意味」を明示的に定義する必要があります。次章ではセマンティックレイヤの主要な要素であるメタデータ管理について整理します。
3章:メタデータ管理(Metadata Management)
①LLM時代におけるメタデータ不足の課題
LLMがデータ分析において直面する最大の課題は、データの意味を理解するために必要なコンテキスト情報の欠如です。現状、以下の情報不足が深刻な問題となっています。
-
セマンティック理解の限界
-
LLMは言語理解に優れていますが、データの内容と文脈を理解するために重要なメタデータが不完全、欠落、または互換性のない形式であるという問題があります[11]。例えば「カリフォルニア州の資産上位50銀行を表示して」という質問があった場合、元のデータに銀行名、銀行ID、州名、資産価値などのデータフィールドとクエリとの関連を示す情報が無ければ、LLMはこれらの関連性を十分に考慮することができません。
-
-
構造化知識との連携不足
-
LLMは非構造化データの広大な領域で主に動作しますが、構造化データとシームレスに統合することに本質的な困難を抱えている状況です[12]。特に、複数のデータソースを接続し、LLMが異なるSQLを処理することは、処理パフォーマンス観点で問題になると主張されています[13]。
-
-
信頼性とハルシネーションの問題
-
LLMチャットボットから得られる結果を信頼することの困難さが根本的な課題であり、LLMが企業環境で効果的に機能するかどうかは、データモデルと一緒に提供されるメタデータの品質と互換性に大きく依存しているのが現状です[11][14]。
-
②主要なメタデータの分類
これらの問題を解決するには、データ間の関係性やコンテキストを補うメタデータの存在が欠かせません。DMBOKでは、メタデータを以下の4種類に分類しています。
1.技術メタデータ(Technical Metadata)
データベース、スキーマ、テーブル、列などのデータ資産の物理的構造を詳述し、データ型やフォーマットなどの重要な実装特性を技術担当者が理解するのを助ける情報です[15]。
2.ビジネス・セマンティックメタデータ(Business/Semantic Metadata)
ビジネス言語とデータ言語のギャップを埋める翻訳者として機能し、一貫性があり整合されたビジネスデータ定義をもたらす役割を果たします[15]。LLMがデータを正しく理解するためのセマンティックレイヤーの中核となる要素であり、具体的には以下の3つを定義します。
-
ビジネス用語の定義:「顧客」「売上」といったビジネス用語が、具体的にどのデータを指すのかを明示する。例えば、
customerテーブルが「見込み客を含むのか」「解約済み顧客を含むのか」といった定義 -
メトリクスの計算ロジック:「売上」「利益率」などの指標がどのように計算されるかを定義する。例えば「売上 = 単価 × 数量 - 割引」「利益率 = (売上 - 原価) / 売上」といったロジックを明示することで、LLMが一貫した集計を行える
-
データ間の関係性:テーブル間のJOIN条件やカーディナリティ(1対多、多対多など)を定義する。これにより、LLMが適切なテーブル結合を行える
3.運用メタデータ(Operational Metadata)
データ資産の処理と使用に関する情報で、更新頻度、パフォーマンスメトリクス、人気度、上位ユーザーなどの使用統計 が含まれます。ランタイム状態とデータパイプラインおよび製品のパフォーマンス情報が重要です[15][16]。
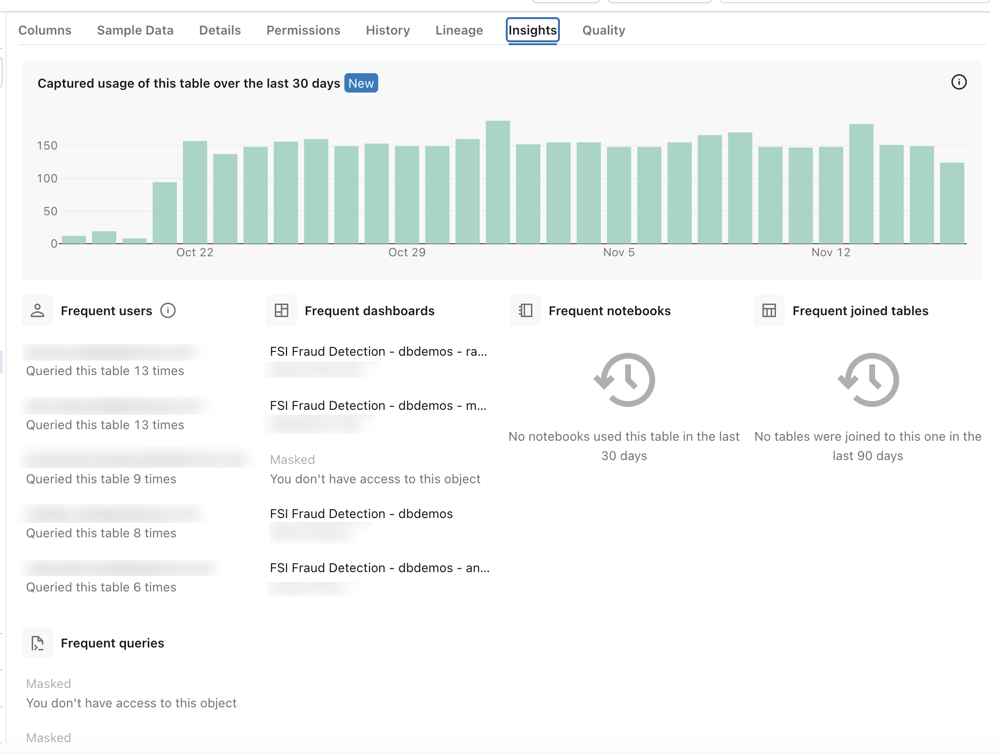
出所:『View frequent queries and users of a table』Databricks
4.ガバナンスメタデータ(Governance Metadata)
データガバナンス政策、コンプライアンス、データ品質に焦点を当て、データ品質メトリクス、系譜、分類、GDPR、HIPAAなどの規制情報を含みます[15][17]。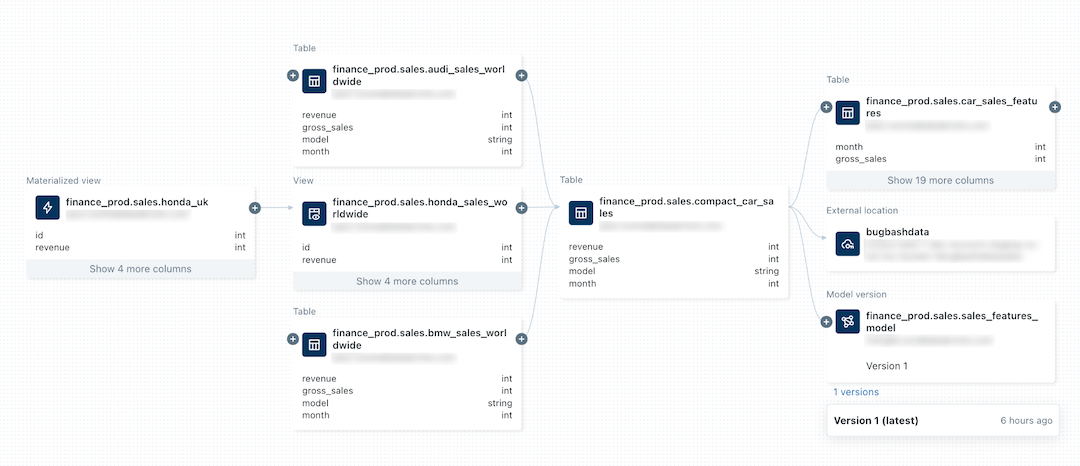
出所:『View data lieage using Unity Catalog』Databricks
本章では、LLM時代におけるメタデータ管理の重要性と、4種類のメタデータ (技術・ビジネス/セマンティック・運用・ガバナンス)の役割について解説しました。 Apache Iceberg[22]、Delta Lake[23][24]、Apache Hudiなどのオープンソーステーブルフォーマットに よるスキーマ進化・バージョン管理と、Unity Catalog[17]やDataHub[25]などのデータカタログに よる統合的なメタデータ管理を組み合わせることで、LLMが必要とするコンテキスト情報を 整備する基盤が整いつつあります。 しかしながら、メタデータが整備されていたとしても、参照するデータ自体の品質が 低ければLLMは誤った分析結果を生成してしまいます。次章では、LLM時代において より厳格な要求が求められるデータ品質管理について解説します。
4章:データ品質管理(Data Quality Management)
①LLM時代におけるデータ品質管理の重要性
文書を要約するのとは異なり、データベースのクエリは正確な結果を返すことが期待されます。しかしながら、データ自体の品質が良くない場合、AIアシスタントが収益数値を誤報告したり、フィルターを誤解釈する可能性が生まれます。このため、従来にない厳格な品質要求が生まれています[18]。
②DMBOKにおけるデータ品質管理の観点と検知方法
これらの重要性は、人間を介さずLLMが自動で分析を行うようになり、データ処理がブラックボックス化することでさらに高まっています。DMBOKでは、データ品質の観点で9つの品質軸と検知アプローチを提示しています。
|
品質次元 |
検知方法 |
LLM特有の検証ポイント |
|---|---|---|
|
Accuracy(正確性) |
・参照データとの突合 ・マスターデータ検証 ・ビジネスルール適用 |
・LLMクエリ結果の事実確認 ・推論根拠の追跡可能性 ・数値計算の検算 |
|
Validity(妥当性) |
・データ型制約チェック ・フォーマット検証 ・範囲値検証 |
・自然言語クエリの構文解析 ・スキーマ準拠性確認 ・APIレスポンス形式検証 |
|
Completeness(完全性) |
・Null値監視 ・必須フィールド確認 ・レコード数検証 |
・コンテキスト情報の充足度 ・メタデータ完全性 ・欠損データの影響評価 |
|
Integrity(整合性) |
・参照整合性チェック ・外部キー検証 ・データ系譜追跡 |
・系譜情報の正確性 ・Cross-table関連性 ・データ来歴の信頼性 |
|
Uniqueness(一意性) |
・主キー重複検出 ・ハッシュ値比較 ・重複パターン分析 |
・エンティティ解決精度 ・同義語・異表記統合 ・曖昧性解消 |
|
Timeliness(適時性) |
・SLA監視 ・更新頻度測定 ・データ遅延アラート |
・リアルタイム要求への対応 ・バッチ処理の適時性 ・時系列データの連続性 |
|
Reasonableness(合理性) |
・統計的外れ値検出 ・ビジネスロジック検証 ・異常パターン監視 |
・「2050年生まれの学生」「212階建ての建物」などの意味論的検証 ・LLM推論結果の妥当性 |
|
Consistency(一貫性) |
・クロスシステム比較 ・データ標準化確認 ・フォーマット統一性 |
・複数データソース間の整合 ・セマンティック一貫性 ・用語・概念の統一 |
|
Currency(最新性) |
・最終更新時刻監視 ・変更検知 ・版数管理 |
・リアルタイム性要求 ・データの鮮度評価 ・時系列整合性 |
これらの品質軸に対して、従来ではアドホックなテスト設計・依存関係の解析など多くの技術的なハードルが存在しており、問題を認識していながら十分な対策が困難でした。近年ではさまざまなツールによる対策が可能となってきています。
|
品質次元グループ |
検知ツール |
実装アプローチ |
|---|---|---|
|
Core Quality (Accuracy, Validity, Completeness) |
・Great Expectations[26] ・dbt Tests[10] ・Monte Carlo[20] |
パイプライン統合により、Airflow[27]、dbt[10]などのオーケストレーションツールとシームレスに統合し、ETL/ELTワークフローの一部としてデータ品質チェックを実行 |
|
Structural Quality (Integrity, Uniqueness, Consistency) |
・Datafold ・DataHub ・Unity Catalog |
データ系譜管理とメタデータ統合による構造的品質保証 |
|
Temporal Quality (Timeliness, Currency) |
・Monte Carlo ・Metaplane ・Delta Lake CDF |
ストリーミングによりデータが継続的にキャプチャ、取り込み、処理、表示され、ほぼリアルタイムの意思決定を可能にする[21] |
|
Semantic Quality (Reasonableness) |
・Amazon Bedrock Automated Reasoning checks[28] |
ビジネスロジック統合とAI駆動異常検知 |
まとめ
本記事では、LLMによるデータ分析効率化が進む中で、従来のDMBOKフレームワークの中で特に重要性が高まっている領域を整理しました。
LLMのデータ分析への応用は急速に進展しており、以下のようなユースケースが実用化されつつあります。
-
Text-to-SQL[29]: 自然言語からSQLクエリを自動生成し、非技術者でもデータベースに直接問い合わせが可能に。2023年以降、生成AIのトップ3アプリケーションの一つとして注目されています。
-
自動EDA(探索的データ分析)[30]: データセットの要約、パターン検出、可視化生成をLLMが自動実行。TiInsightのようなシステムでは、スキーマの階層的要約からクエリ分解、可視化までをエンドツーエンドで自動化します。
-
Data Agent: DS-Agent、Data Interpreterなど、LLMがデータ前処理からモデリング、評価まで一連のデータサイエンスワークフローを自律的に実行するエージェントシステムが登場しています。
-
可視化の自動生成[31]: データに適したグラフを自動提案・生成し、VLM(Vision-Language Model)によるセルフレビューで品質を担保するシステムも出てきています。 これらの自動化が進むほど、「LLMに渡すデータの品質」が成果を左右する決定的要因となります。不完全なメタデータ、古いデータ、不整合なスキーマは、LLMのハルシネーションや誤った分析結果に直結します。
これらLLM活用を安定して運用していくためには、データアーキテクチャ設計による段階的なデータ成熟アプローチ、オープンソーステーブルフォーマットとデータカタログを活用したメタデータ管理、データ品質保証の3領域の重要性が従来以上に高まっています。完璧なシステムを一度に構築するのではなく、段階的改善アプローチを採用し、継続的にデータ管理能力を向上させていくことが鍵となります。これにより、企業はLLM技術の恩恵を最大限に活用しながら、信頼性の高いLLMドリブンな意思決定を実現できるでしょう。
参考文献
[1] Hong, S. et al. (2024). "Data Interpreter: An LLM Agent for Data Science." arXiv:2402.18679. Data Interpreter: An LLM Agent For Data Science
[2] Altay, G. et al. (2025). "Leveraging large language models for data analysis automation." PLOS ONE. Leveraging large language models for data analysis automation
[3] DAMA International (2017). DAMA-DMBOK: Data Management Body of Knowledge (2nd Edition). Technics Publications.
[4] Atlan, "Data Management for LLM Deployments" Data Management for LLM Deployments: Issues, Best Practices
[5] Databricks, "Medallion Architecture" What is the medallion lakehouse architecture? | Databricks on AWS
[6] dateonic, "What is Medallion Architecture in Databricks and How to Implement It" Databricks Medallion Architecture: Essential Guide
[7] BASE プロダクトチームブログ, "LLMを用いた分析基盤におけるSQL自動生成の取り組み" LLMを用いた分析基盤におけるSQL自動生成の取り組み - BASEプロダクトチームブログ
[8] メルカリ Analytics Blog, "肥大化したデータ基盤の刷新 ‐安定と利便を分離するBasic Tables Coreの設計‐" メルカリの効率的なデータ活用を支えるデータインタフェース Basic Tables|Mercari Analytics Blog
[9] メルカリ Analytics Blog, "One Big Tableを用いた機械学習パイプラインの改善" 肥大化したデータ基盤の刷新
‐安定と利便を分離するBasic Tables Coreの設計‐|Mercari Analytics Blog
[10] dbt Labs, Official Documentation dbt Developer Hub
[11] FactSet, "Using Large Language Models to Converse with Your Data" Using Large Language Models to Converse with Your Data
[12] Wisecube, "Leveraging the Power of Knowledge Graphs: Enhancing Large Language Models with Structured Knowledge" Leveraging the Power of Knowledge Graphs: Enhancing Large Language Models with Structured Knowledge
[13] Medium (Wren AI), "How We Design Our Semantic Engine for LLMs" How we design our semantic engine for LLMs?
[14] Medium (Dave Allemang), "Avoiding LLM Hallucinations: Data vs Metadata" Avoiding LLM Hallucinations — data vs. metadata
[15] Alation, "What is a Data Catalog?" What Is a Data Catalog? Importance, Benefits & Features | Alation
[16] Databricks, "View frequent queries and users of a table" View frequent queries and users of a table | Databricks on AWS
[17] Databricks, "View data lineage using Unity Catalog" View data lineage using Unity Catalog | Databricks on AWS
[18] Medium (Madhukar Kumar), "How to Build Accurate RAG over Structured and Semi-Structured Databases" Chapter 1 —How to Build Accurate RAG Over Structured and Semi-structured Databases
[19] Leandatacentricity, "Data Quality Semantics" http://www.leandatacentricity.com/articles/data-quality-semantics.html
[20] Monte Carlo, "Best Quality Assessment Tools" The 10 Best Data Quality Assessment Tools Of August 2025
[21] Databricks, "Data Quality Management" Data Quality Management With Databricks | Databricks
[22] Apache Iceberg, Official Documentation Apache Iceberg - Apache Iceberg™
[23] Delta Lake, Official Documentation Home | Delta Lake
[24] Apache Hudi, Official Documentation Apache Hudi | An Open Source Data Lake Platform | Apache Hudi
[25] DataHub Project, Official Documentation DataHub | Modern Data Catalog & Metadata Platform
[26] Great Expectations, Official Documentation Great Expectations: have confidence in your data, no matter what
[27] Apache Airflow, Official Documentation Home
[29]Text to SQL: The Ultimate Guide for 2025
[31]: LLM-Based Data Science Agents: A Survey of Capabilities, Challenges, and Future Directions