初めてのKaggle挑戦記:AI活用しながらMABeマウス行動検知コンペに参加してみた
 この記事をシェアする
この記事をシェアする



はじめに
ARISEanalyticsの小野です。
今回2025年9月~12月に開催されたMABe Challenge - Social Action Recognition in Mice[1]に弊社メンバー(福嶋、柴田)と参加し、銀メダル(17位/1412チーム)を獲得することができました。
私自身初めての外部コンペ参加であり、学ぶことが多かったため、今回挑戦記として学んだことをまとめました。
1. 挑戦のきっかけ
今回「MABe Challenge」を選んだのは、本コンペがテーブルデータでかつ、マウスの行動推定という問題設定がイメージしやすいものだったからです。私自身Kaggleに興味がありつつも、直近開催されていたコンペはLLM関連のものが多く、初めての参加としてはややハードル高いと感じていました。そこでテーブルコンペの紹介があり、これなら初心者でも取り組みやすいと思い、参加することとなりました。
2. コンペの概要
今回参加したコンペは、複数のマウスの姿勢データから、30種類以上の複雑な社会行動(「Attack:攻撃」、「Investigation:探索行動」など)を自動分類するタスクでした。動画解析コンペでは入力が画像であることが多いのですが、今回は通常の動画分析コンペとは異なり、ラボ毎に実験に使用したマウスの特徴データや、あらかじめ抽出された各個体のキーポイント(鼻、耳、体、尾の付け根など)の座標データといったテーブルデータのみが入力となりました。 評価指標は平均F1スコアで、30fpsなどの時間解像度の動画の各フレームの中で「Attack」「Investigation」「Mount」などキーポイント(マウスの追跡部位)で見ると似た行動を精度高く切り分けることが求められました。
イメージ[3]: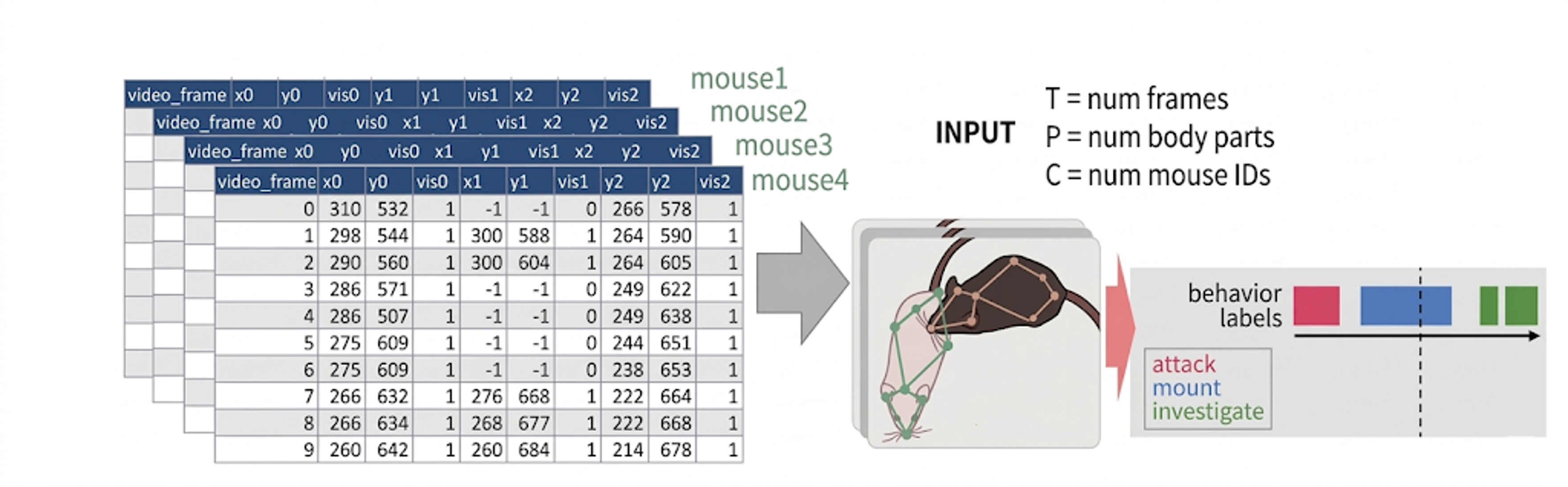
Fig 1: タスクのイメージ — マウスのフレーム毎のキーポイント座標のテーブルデータ入力とし、動画分類モデルによりマウスの行動ラベルを出力する
(※イラストは生成AIにより作成したイメージ)
評価方法:
Fβ スコア(フレーム単位)
Fβ = (1 + β²) · TP (1 + β²) · TP + β² · FN + FP
最終スコア(ラボ平均)
Score = 1/|L| Σl∈L ( 1/|Al| Σa∈Al Fβ(l,a) )
- L:ラボの集合
- Al:ラボ l でアノテーションされた行動(action)の集合
- Fβ(l,a):ラボ l、行動 a における Fβ スコア
- ※本コンペでは β = 1 として算出
3. 取り組み概要
コンペ全体では大きく分けると以下のような流れで取り組みました。特に今回はAIの力も多分に借りて取り組んだため、どのように使ったかについて言及しながら紹介していきます。
コンペ前半(9月~11月):一旦メダル圏内に入ることを目標に個人で参加
コンペ後半(12月~終了):社内で同じコンペに取り組まれていた方と銀メダル以上を目指してチームマージして参加
コンペ前半(9月~11月)
最初は「マウスの行動分類とはどういうタスクなのか」というコンペそのものを理解するところから始め、下記のような流れでサブミットまで行いました。
1. 環境構築
KaggleではNotebookというKaggle上でコード作成・実行が可能な環境が用意されており、すぐにデータを読み込んで実行ができます。一方でNotebookの変更履歴の管理やAIによるコード補完等が使用できない点がデメリットとしてありました。Kaggle初参加というのもあり、AIにわからないことはすぐ聞けるような環境が欲しいと思ったため、今回 Cursor + GitHub(プライベートリポジトリ)+ Docker でローカル環境を作りました。
役割分担としては、Cursorでコードを書き、Dockerでコンペで使用するライブラリ(pandas・numpy・scikit-learn・LightGBM・JupyterLab etc)が入った実行環境を統一し、GitHubには提出用コードを置いていました。提出時は Notebook上でリポジトリをKaggle Notebookにクローンし、そのまま実行して提出する流れにしました。Cursorでは主にClaude Sonnet4.5のモデルを使用し、コード作成等を行いました。
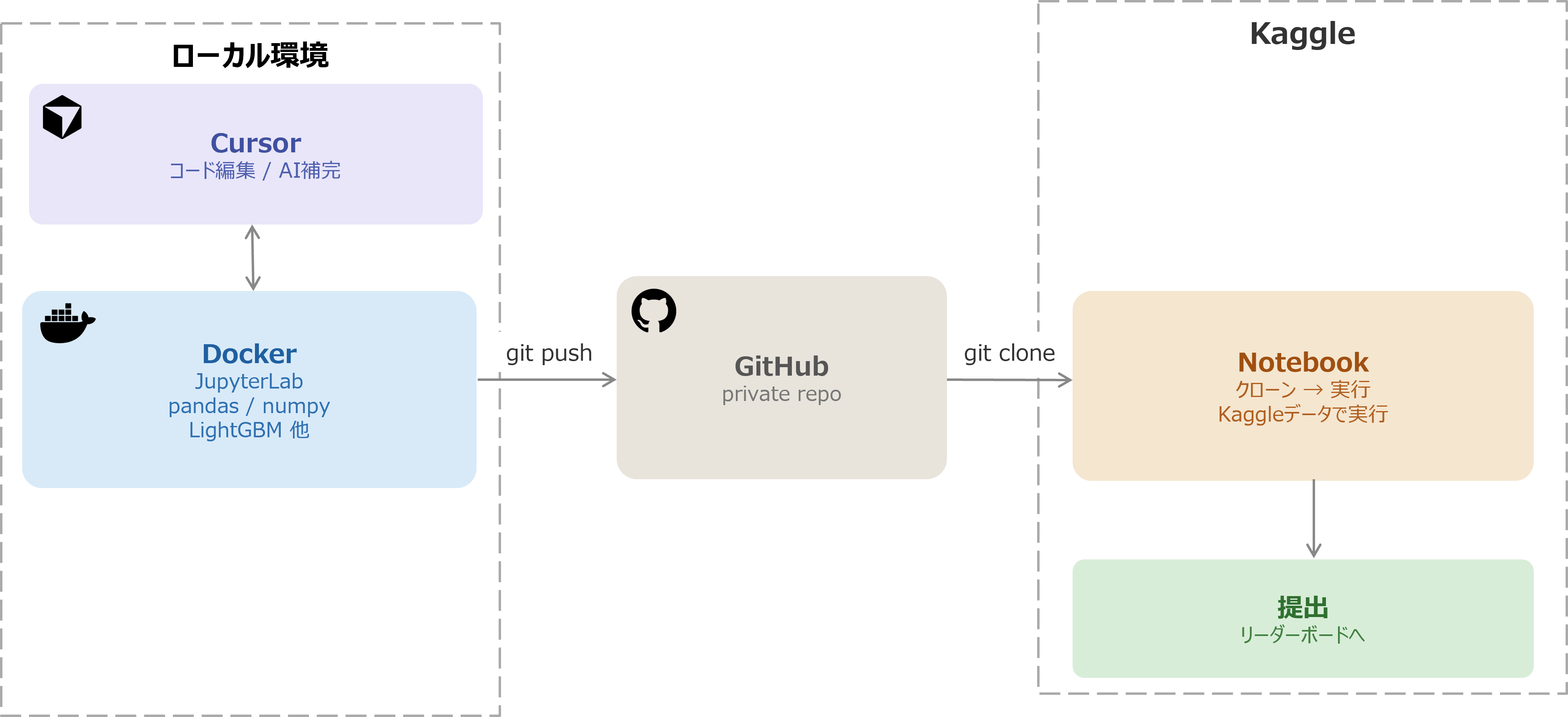
Fig2:Kaggle分析環境イメージ
ローカル環境作成により、実際にCursorのチャットで不明点や仮説立てを手伝ってもらいながらコードを書き、その変更をGitで追跡できるようになりました。Notebookを直接触っていたときは「どこを変えたか」がすぐわからなくなっていたり、コードの不明点をAIに質問しづらかったのですが、取り組みやすくなったと思います。
2. データの理解・EDA(Exploratory Data Analysis)
最初に学習データの全体像を理解するために、コンペのホームページに掲載されているデータ説明文をそのままAIに渡して概要を作成してもらいました。作成した概要はMarkDown形式でローカルに保存し、AIへのインプットとできるようにしておきました。(※データのカラムと概要のみ)
Kaggleのドキュメントはすべて英語で書かれており、データの全体像を把握するのに時間がかかる点があったのと、一度AIに整理してもらったMarkDownファイルをローカル環境に置いておくことで、その後の作業でAIに質問をする際により実データの形式に沿った形で出力させやすいためです。
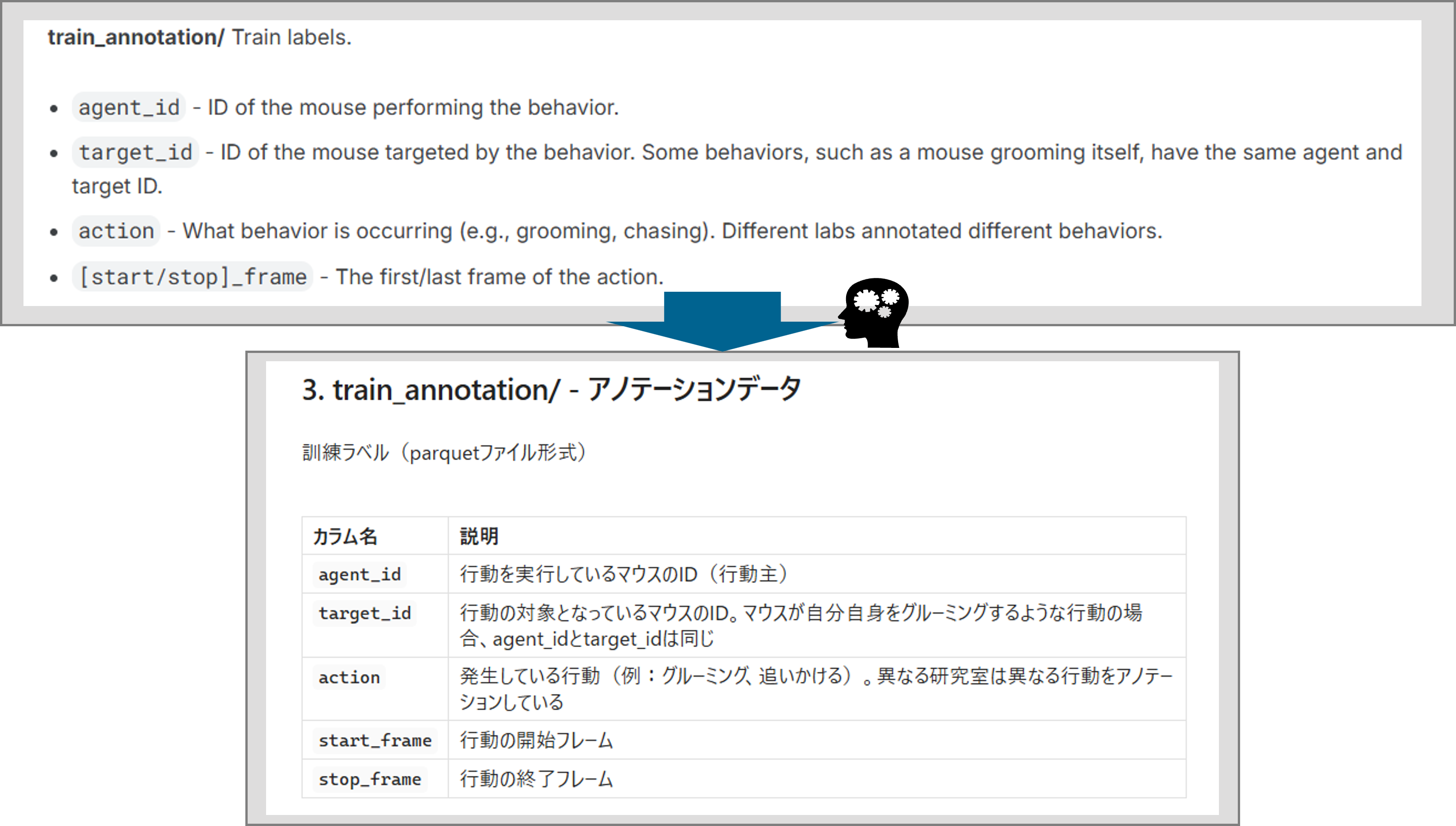
Fig3: 生成AIによるデータ概要作成イメージ
概要の把握後はさらに詳しく学習データの詳細の確認を行いました。EDAを行っている公開Notebookのうち投票数が多いものをピックアップしてそのNotebook[4]をベースとして追加で分析する方針で行いました。
データの詳細を調べた結果、今回のデータセットには次のような課題があることが見えてきました。
- 研究室による違い
- 各ラボでトラッキングしているキーポイントが異なる
- ラボ毎にトラッキング手法が異なる(fpsや座標)
- 一部のLabでは複数のマウスを追跡している
- アノテーションがされていない行動が存在する
- CalMS21、CRIM13、MABe22といったラボではラベルが無し
3. 公開コード(ベースラインモデル)でサブミットする
続いてすぐにモデルを作成したのでは無く、現状で最もスコアが高く、コードをそのままサブミットできるものを公開Notebookから選び、そのまま提出をしてみました。公開コードをそのまま提出する理由として以下の3つの点でメリットがあると感じました。
- 提出の操作に慣れる
- GPUの設定や、提出回数の制限、実行時間、スコアがどのように返ってくるのかといった基本的な感覚が理解できました。
- スコアの基準を理解できる
- コンペにおいてどんな特徴量、モデルを使用するとどれくらいのスコアを出すのかという感覚を理解できました。同時にスコアの妥当性についての感覚も理解できるため、その後の精度上げの基準値ができたと思います。
- コンペの解き方の型を理解する
- 最初はデータの作り方、提出ファイルの形式などのお作法がよくわからなかったため、提出できる状態のもので実践することで提出時のコードに何が必要なのかを理解することができました。
4. ベースラインモデルの改善
Kaggleの操作やコンペに慣れてきたところで、公開Notebookのコード改善に取り組みました。最初に公開Notebookの内容は特徴量が埋め込まれていたり、コメントアウトなど不要な部分も残っていたりと読みづらいこともあったため、設定はConfigに持たせるようにしたり、クラスやメソッドを使うようにしたりとリファクタリングを行ってもらいました。それによりそのまま直接コードを読むよりも構造化されており、ベースラインモデルを読み解くのが楽になりました。
その後修正したコードとデータ構成をAIへの入力として、前項で上がった「データの課題をどのように処理しているのか」と「どういう改善点があるか」を列挙してもらいました。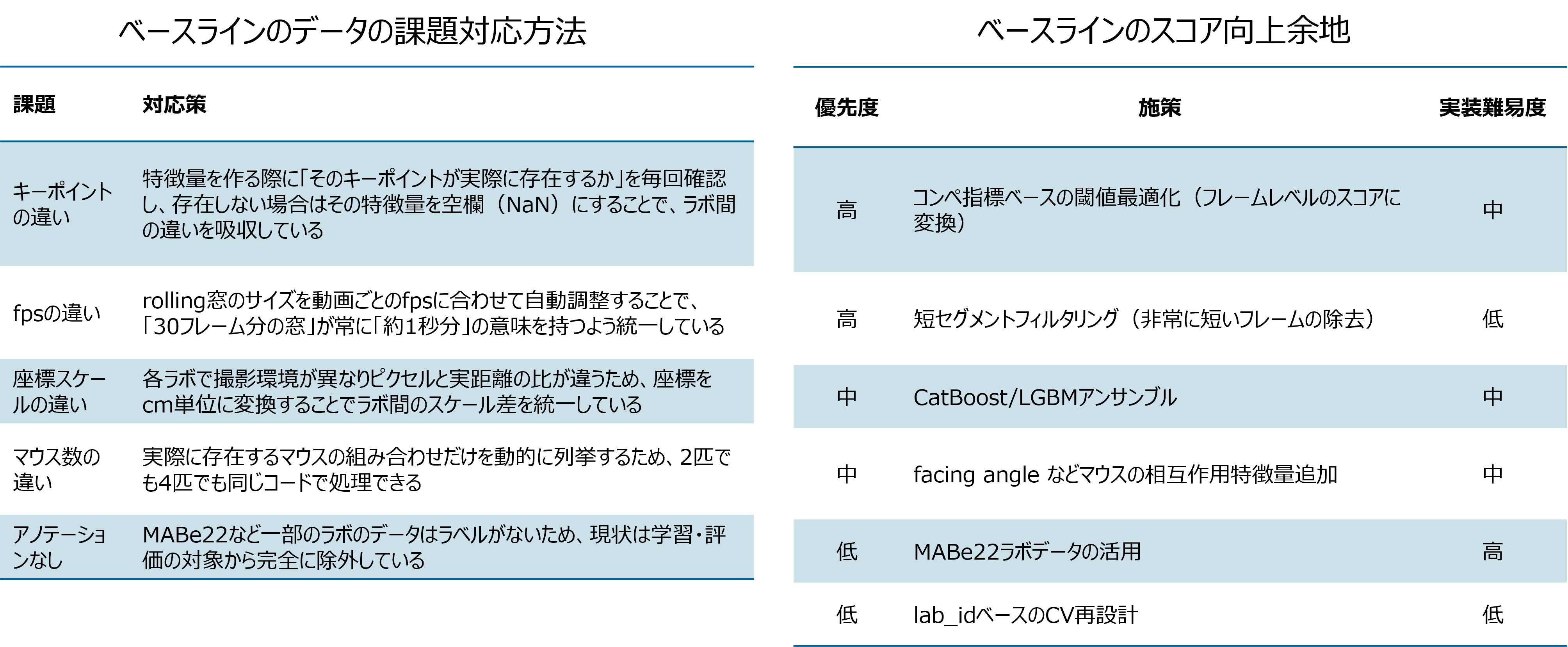
生成AIによって出力されたベースラインのデータ課題対応方法(左表)とスコア向上余地(右表)
データの課題についてはある程度考慮がなされていることを確認したので、ベースラインのスコア向上余地の一番上から着手してみました。工夫の方法は解法に後述しますが、結果はフレームレベルでは無く、ラボ単位でのスコアに変換したことが最もスコア向上に効きました。これにより、銀メダル圏内に入ることができました。もう少し他の案も試行錯誤をしたかったのですがここまでの取り組みまでで多くの時間を使ってしまったこともあり、試行錯誤の回数が積めませんでした。
コンペ後半(12月~終了まで)
後半は個別に取り組んでいた社内メンバーとチームマージし、さらなる精度向上に取り組みました。
マージ直後は、それぞれのスコアと試した手法を共有しました。ベースラインモデルでの結果を共有した後もその後の改善の方向が私と異なっており、大変勉強になりました。
具体的に、
- 精度改善の軸が異なる
- 自分はAIに出してもらった改善案を軸に進めていたのに対し、メンバーは経験知を元に交差検証やスタッキングなどモデルの見直しにも多く取り組まれていました。
- 欠損値処理手法の広さ
- ベースラインでは欠損値をNaNのまま扱っており、私は処理をしていませんでした。しかしメンバーは単純な欠損値補間(impute)やベイズ補間、GCNの補間、Hampel filter (スライディングウィンドウのようにに外れ値除去する手法)等、私にとってあまり聞きなれない方法で補間を試されていました。
他にも一人で進めていたときは全く気づけなかったポイントが多くあり、手法や視点を多く学ぶことができました。まだ「精度向上に対する良し悪しの判断力が足りない」と実感しつつもデータ深堀や、対応策の調査に引き続き取り組み、最終的に銀メダルを獲得することができました。
4.解法
それでは今回自チームの解法について紹介します。
解法アプローチの全体像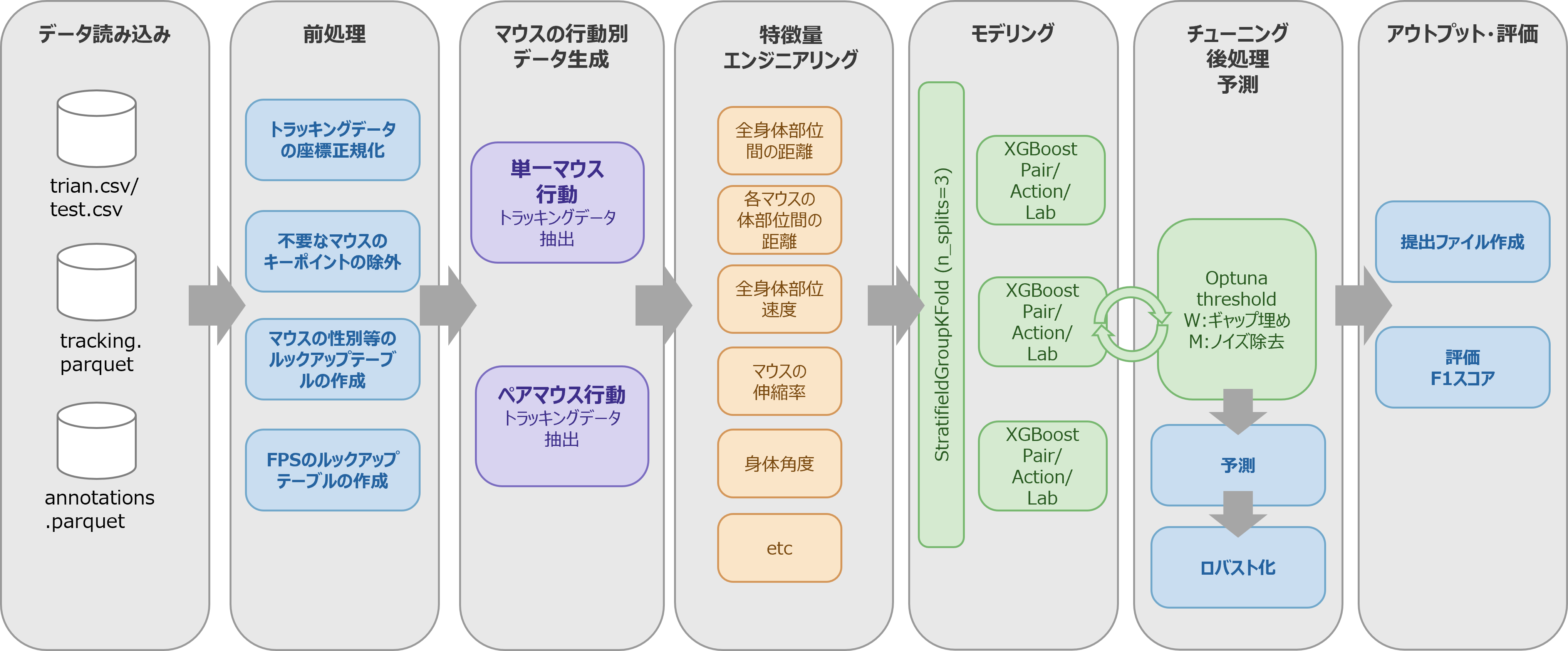
Fig4:解法の全体フロー
マウスのトラッキングデータからマウスが単体で行う行動と、2体以上のマウスが行う社会的行動の2つに分けた速度・距離・角度などの特徴量を生成し、XGBoostでラボ、行動ごとに二値分類しました。その後、学習時に最適化したパラメータを用いて、XGBoost出力結果を補正し、提出ファイルを作成するという構成をとりました。
精度向上に効いたポイント
今回は特に下記3つの課題に対しての対応策が精度向上に大きく寄与しました。
| 課題 | 今回の対応策 |
|
ラボ毎にアノテーション方法が異なる |
モデリングの単位をラボ毎に変更 |
|
ラボ毎のキーポイントの違い |
ベースラインでは基準となるbody_centerが無い場合はNaNとして扱っていたが、他のキーポイントからbody_centerを補完するように変更 |
|
行動ラベルごとの時系列性を考慮できていない |
スコア・予測値補正 |
1.モデリングの単位(body_parts → lab_id)
課題点:ベースラインでは「同じ追跡部位をもつ動画」をまとめて1つのモデルで学習するようになっており、ラボ単位の特徴を学習できていない点がありました。ラボ毎に追跡部位が同じでも撮影環境・マウスの品種・行動の定義が異なっていたのと、評価方法がラボ単位でF1スコアを平均するようになっている2点を踏まえるとモデリング単位の変更は精度に大きな影響を与えそうでした。
解決方法:上記の課題に対して私たちの解法ではラボ単位×追跡部位でモデルをさらに分けることで、各ラボのデータ特性も追加した学習ができるようにしました。わりと単純な追加だったのですが、0.2ptもスコアが上がったのでかなり大きな向上でした。
2.body_center の欠損の扱い
課題点:今回のデータには追跡キーポイントに body_center(重心) が存在しないラボがいくつかありました。body_centerはマウスの速度や向きなど多くの特徴量の計算に使われる重要なキーポイントですが、ベースラインではbody_centerが存在しないラボの該当フレームを欠損値のまま扱っていたため、その分だけ特徴量が減り、精度向上の余地がありました。
解決方法:本解法ではnose(マウスの鼻)とtail_base(マウスの尻尾) の中点から自動補完をするように変更しました。この補完によって重心が無いラボでも重心系の特徴量を生成できるようになったことで、学習データの増加によってスコアが上昇しました。
3.分類モデルに時系列要素を追加する
課題点:今回のテーマはマウスの行動分類のため、多クラス分類器であるXGBoostを使用していました。しかし、実際にマウスの行動データとして与えられている動画座標データ上ではマウスがattackという行動をしているときはマウス同士が加速度を持っていますし、「Chase:追跡」であれば一方が時間とともに座標が近づいたりする特徴が必要です。つまり、マウスの行動は1フレームで完結するものでは無く、複数のフレームにまたがって連続して起きるという性質を考慮する必要がありました。
しかし、ベースラインではそのまま分類モデルを適用しているので、マウスのフレーム毎に違うラベルがつけられてしまうことが問題としてありました。
解決方法:分類モデルによって算出されたラベルを補正することで、時系列特徴量を疑似的に再現しました。具体的にはモデルが途中の数フレームだけ 0 と予測してしまった場合、それは予測ミスである可能性が高いため、W(ギャップ補完)によってとび値を補完しました。また、逆に1〜2フレームだけの孤立した予測はノイズである可能性が高く、M(ノイズ除去)で短すぎる予測を消すことで偽陽性/過検出を減らす工夫を行いました。さらにこのW・Mをモデルの閾値と同時にOptunaで最適化を行っていたことも効いたと考えられます。
上記などの工夫により最終的にLBで0.488 → 0.506・PBで0.463 → 0.481のスコアアップができました。
5.AI活用してみて感じたこと
最近のコンペでは、AIに作ってもらったベースラインを公開している参加者も多く、そのAIによって作らせたモデルのスコアがコンペの基準になっているような印象を受けました。今回Cursorを使ってAIにコーディングや仮説立ての手伝いなどをしてもらったのですが特にAI活用するための環境構築と、精度向上の所感部分に課題を感じました。
AI活用するための環境構築
AIを使ったコーディング環境の選択肢は増えていて、何を選ぶかや、どこまでAIに渡していいか、どのように実験をまわしていくのが良いかについてかなり迷いました。今回は使い慣れていたCursorを選びましたが、課題点も多くありました。
- 良かった点
- Git と連携しているので実験ごとにコードの変更を追跡できた
- Dockerで環境を固定したため「ローカルでは動くのにKaggleで動かない」問題がほぼなかった
- 仮説の壁打ちやコード生成をチャットで気軽に行えた
- 課題点
- 自前のGPU環境を持っていないので、KaggleのNotebook上でいちいちcloneして実行するため、実験した結果の管理はKaggleのNotebook上になってしまっていた
- Kaggleはローカルで複数ファイルに分けて開発していても最終的にNotebookの1ファイルにまとめる必要があり、1ファイルのコードが数千行を超えるとCursorのコンテキストウィンドウにひっかかるのか、全体を把握しきれていないような回答が返ってくることがあった
今回はAIをどう使うかの知見がまだ足りておらず、Kaggle GPUの活用方法、プロンプトやコンテキストの渡し方、実験結果の管理方法など、工夫できる余地が残っています。最近はClaude Codeのようにファイルの読み書きやコマンド実行まで自律的に動くツールも出てきているので、次回はこのあたりの使い方も含めて環境設計を見直したいと思っています。
精度向上の所感
取り組み概要で述べたようにベースラインからの改善仮説をAIに出してもらい、実装・提出をしましたが、スコアはあまり上がりませんでした。チームマージ後、メンバーがAIでは提示されなかったアプローチで精度を伸ばしているのを見て、精度向上をAIに丸投げするのはまだ難しいと実感しました。
- AIが得意だったこと
- 仮説の選択肢を素早く列挙する
- 実装のコード生成・修正・解説
- 仮説の実装の難易度を出すこと
- 人間がやる必要があったこと
- データの中身を実際に見て課題を見つけること
- 複数の仮説の中から自分の力量にも合わせてどれを試すか優先順位をつけること
今回の使い方はチャットで仮説を聞いて自分で判断して実装をAIに行ってもらうスタイルで、AIがデータを直接見て問題を発見する流れにはなっていませんでした。結果として「何を改善すべきか」の判断は自分の知識に依存していたため、ドメイン知識が薄い状態ではAIへの指示も的外れになりがちだったのではないかと思います。
また、精度向上はデータへの理解が起点になるため、よりデータファイルの読み込み方を工夫して、「データを見る→課題を洗い出す→実装」の流れをもう少しAIに委ねてみるやり方も試したいです。
6. まとめ
本記事では、Kaggle初心者がAIを活用してMABe Challengeでメダルを取るまでに取り組んだことを紹介しました。AIを活用することで初心者でも参加のハードルが低くなる一方で、精度向上のための深堀部分では経験と知識がまだまだ必要だと感じました。今後出てくる新しいAIツール×分析の知見を得るためにも引き続きコンペに参加していきたいと思います。
引用・参考文献
[1] https://www.kaggle.com/competitions/MABe-mouse-behavior-detection/overview
[2] https://www.kaggle.com/code/ravaghi/social-action-recognition-in-mice-xgboost
[3] https://elifesciences.org/articles/63720#content
[4] https://www.kaggle.com/code/antoninadolgorukova/mabe-an-exploratory-data-safari
[5] https://go-drive-tech.hatenablog.com/entry/2026/01/28/180859


