現環境最強のテーブルデータ向けモデルTabPFNの紹介
 この記事をシェアする
この記事をシェアする



初めに
こんにちは。技術開発 Teamの福嶋です。皆さんはテーブルデータの分類タスクを行う際どのようなモデルを使っていますでしょうか?
当社においては、初手としてLightGBMやXGBoostなどの勾配ブースティング木(GBDT)を用いていることが多い印象です。
ChatGPTやStable Diffusionなどテキスト・画像データに対して圧倒的な精度を出している深層学習系のモデルはどうかというと、残念ながらあまり利用されていない印象です。
実際、テーブルデータに最適化された深層学習の手法で有名なところとしてTabnet[1]などが挙げられますが、精度・処理速度という点においてGBDTには遠く及ばず、業務利用するメリットがあまりありませんでした。
そんな常識を覆し、2023/5時点[2]で、オープンデータの平均スコアで最も高い精度を出した深層学習をベースのモデルであるTabPFN[3]について今回ご紹介します。
TabPFNの凄さ
TabPFNの凄さは、「学習速度」にあります。
下図は、テーブルデータであるOpenML-CC18 Benchmark[4]を学習した際の精度を示したものになります。

![学習時間当たりのROC-AUC[縦軸]の結果のグラフ](https://www.ariseanalytics.com/hs-fs/hubfs/image-20231004-094625-1.png?width=770&height=102&name=image-20231004-094625-1.png) (図1:OpenML-CC18 Benchmarkを使用した既存手法における学習時間[横軸]当たりのROC-AUC[縦軸]の結果。左上にあるTabPFNが最も早い学習時間で最も高い精度を出せることを示している [3]より引用)
(図1:OpenML-CC18 Benchmarkを使用した既存手法における学習時間[横軸]当たりのROC-AUC[縦軸]の結果。左上にあるTabPFNが最も早い学習時間で最も高い精度を出せることを示している [3]より引用)
TabPFNは、圧倒的に速い学習時間でGBDTモデルを上回る精度がでています。
これは、既存の木・深層学習ベースとは大きく異なる方法で学習していることが理由であり、サンプル数<1000レコード以下, 特徴量<100個, 目的変数<10クラスであれば1秒以内で学習・推論が可能とされています。

また、テーブルデータのモデルを比較したサーベイ[3]によると、公開されているデータセットにおいて精度・学習速度ともに平均的にはTabPFNが最もよいことが示されています。
汎用性もあり、非常に優秀なモデルであることが窺がえます。
TabPFNの原理
それでは実際の仕組みを確認してみます。
TabPFNは、簡単には「構造的因果モデルによる人工データ生成」と「PFN(Prior-Data Fitted Networks)[4]による事後分布近似」を活用した、Transformerベースモデルです。
目標
TabPFNの目標は、学習データ(D=(Xtrain, ytrain))と推論データの説明変数(Xtest)を仮定したときにおける目的変数(ytest)の事後予測分布(PPD)を推定することです。
このPPDは一般的には計算できませんが、妥当な構造的因果モデル空間(SCM)Φを指定することにより、下記式で近似可能であることがPFN[4]によって示されています。

手順
目標を達成するために、TabPFNの学習と予測は大きく3ステップで行われます。最初の2ステップは実データを使用しない事前学習フェーズであり、最後の1ステップで実データを使い事後分布を計算します。
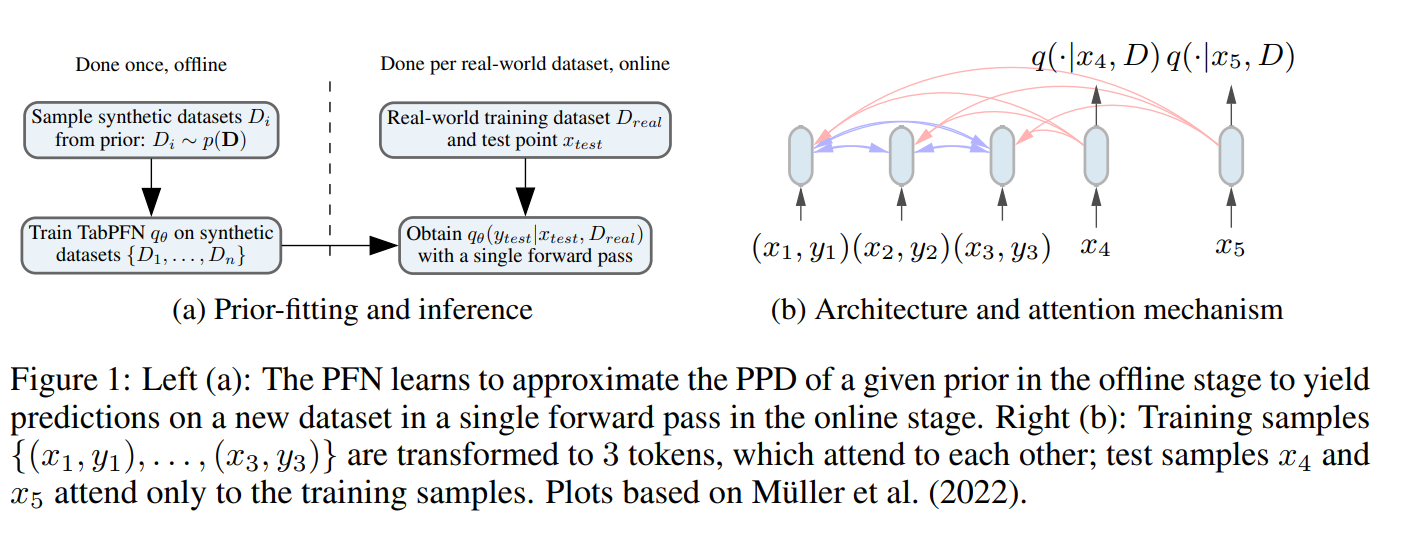 (図3 学習及び推論の概要図。 [3]より引用)
(図3 学習及び推論の概要図。 [3]より引用)
ステップ1:φ∈Φと人工データの生成
まず初めに、SCMの空間Φ(下図(c))からランダムにサンプリングしたφ(下図(b))を用い、人工データD=(X, y)を生成します。
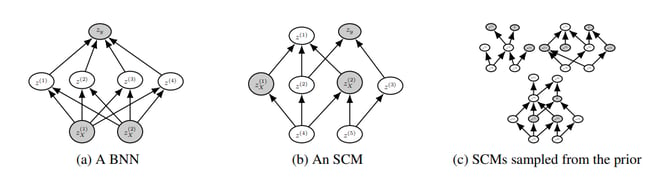
(図4:(a)ベイジアンニューラルネットワーク(BNN)と(b)SCMの因果グラフ構造の違い。(c)はSCMの集合Φのイメージ図。[2]より引用)
各SCMは上図(b)のようなDAG構造とノード間の関係を定義する関数fに基づいています。ノイズ変数(上図(b)のz(*)にあたるものだと思われる)をランダムにN個サンプリングし、SCMに則り伝搬することでX=(Zx(0), Zx(1)・・)及びy=(Zy(0)・・・)を生成しているようです。
ステップ2:生成したDを用いたTabPFNのモデルqΘの学習
次に、1でD=(X, y)をDtrainとDtest=D\Dtrainに分け学習を行います。モデルはTransformerをベースとしたアーキテクチャであり、通常の分類タスクと同様に以下のCrossEntropyLossで更新を行います。

ステップ3:実データによる事後分布推定
最後に、実データD=(Xtrain, ytrain)とXtestを前述のPPDの近似式に適用します。たった一回のフォワード処理のみでPPDの推定ができるため、短時間で学習・推論が終了します。
ステップ2によって学習された事前学習済みモデルは既に著者のgithub[6]に公開されているため、必要な処理は実質ステップ3のみです。
TabPFNの実装
pip installtabpfn==0.1.9from tabpfn import TabPFNClassifier
X_train = train_df[FEATURE_COLS].values
y_train = train_df[TARGET_COL].values
X_test = test_df[FEATURE_COLS].values
model = TabPFNClassifier(
N_ensemble_configurations=56,
device='cuda:0',
)
model.fit(
torch.tensor(X_train, dtype=torch.float),
torch.tensor(y_train, dtype=torch.long)
)
pred = model.predict_proba(
torch.tensor(X_test, dtype=torch.float)
)
TabPFNの欠点
ここまでTabPFNの良い点ばかり書いてきましたが、TabPFNには唯一かつ最大の欠点があります。
それは、サンプル数<1000レコード以下, 特徴量<100個, 目的変数<10クラスの小さなデータセットにしか適用ができないという点です。
レコード数に対し二次関数的に増えていく処理時間の問題や1000行以上のデータセットではあまり得意でなく既存手法と比較し精度が出ない[7]といった課題もあるようです
アンケート分析などの比較的少量のデータを分析する際には利用用途がありそうですが、ビッグデータへの適用にはまだ課題があります。
まとめ
今回は、GBDTを上回る深層学習ベースのモデルであるTabPFNを紹介しました。
大規模データに適用が難しいという欠点もありますが、少量のデータに対してはとても良い精度が得られるため、GBDTに代わるモデルとして使い道を検討していきたいと思います。
参考文献
[1]:[1908.07442] TabNet: Attentive Interpretable Tabular Learning (arxiv.org)
[2]: When Do Neural Nets Outperform Boosted Trees on Tabular Data?
[3]: TABPFN: A TRANSFORMER THAT SOLVES SMALL
TABULAR CLASSIFICATION PROBLEMS IN A SECOND
[4]: OpenML Benchmarking Suites
[5]: TRANSFORMERS CAN DO BAYESIAN INFERENCE
[6]: https://github.com/automl/TabPFN/tree/main
[7]: [論文著者のX[旧 Twitter]における投稿](https://twitter.com/SamuelMullr/status/1584795629775380481)


